
การทีวีในบ้านเรานี่เป็นสิ่งที่ขาดไม่ได้อย่างนึงเลยทีเดียว การฟังข่าวถือเป็นหนึ่งในกิจวัตรหลักของการดูทีวีในไทยเลยก็เป็นได้
ถ้าใครติดตามข่าวจากรัฐบาลเนี่ย ก็จะรู้ว่าข่าวจากรัฐมีหลายประเภทเหมือนกันนะ ตั้งแต่ข่าวจากทำเนียบ ด้านกฎหมาย การศึกษา ความมั่นคง สังคม เศรษฐกิจ เยอะแยะไปหมดเลย
จริงๆแล้วที่เกริ่นมาไม่เกี่ยวอะไรเลย คือว่าวันนี้เราจะลองเอาโปรแกรม deepcut ที่พัฒนาจากทารบริษัท True Corporation มาใช้คัดข่าวจากเว็บไซต์รัฐบาลไทยกัน ซึ่ง data ที่ได้มานี้ยืมมาจาก wannaphongcom/thaigov-corpus มีทั้งหมด 8923 ข่าว เราจะมาดูกันว่าเราจะแยกประเภทข่าวกันได้มั้ย
ในโพสต์นี้เราจะใช้เทคนิค bag-of-words ซึ่งแปลงข่าวให้เป็นเมทริกซ์กัน ซึ่งค่อนข้างเหมาะกับขนาด data ที่เรามีกัน
ส่วนในโพสต์หน้า เราจะลองใช้ fastText จาก facebook บ้างเพื่อความหลากหลาย

สำหรับใครที่อยากทำตามระหว่างอ่านด้วยก็ลองไปดูโค้ดกันใน Jupyter Notebook ได้เลย
เริ่มต้นจากติดตั้งซอฟต์แวร์ก่อน
เริ่มแรกเลยก็ต้องโหลดและติดตั้ง deepcut ก่อนฮะ ลองอ่านวิธีติดตั้งจากใน
repository ได้เลย ส่วนการใช้ deepcut ก็ไม่ยากเลยแค่ต้อง import deepcut และใช้ฟังก์ชัน
deepcut.tokenize เพื่อตัดคำไทย
นอกจากนั้นก็โหลดข่าวจาก repository ของน้อง wannaphongcom โดยใช้ git clone ฮะ
git clone https://github.com/wannaphongcom/thaigov-corpus
ขอบคุณน้องที่โหลดข่าวมาประมาณ 8923 ข่าวแหนะ เอาไว้ใช้เป็นสื่อการสอนได้อย่างดีเลย
โหลดข้อมูลและเช็คประเภทข่าว
ก่อนอื่นเราจะใช้ glob เพื่อดึง path ของข่าวที่เราสนใจซึ่งเก็บอยู่ใน .txt format มาจาก repository ที่พึ่งดาวน์โหลดมาฮะ
from glob import glob
paths = glob('/path_to/thaigov-corpus/*/*.txt')
จากนั้นเราอยากจะดูว่ามีข่าวประเภทอะไรบ้าง หน้าตาของ path เป็นแบบนี้ /thaigov-corpus/9/ด้านการศึกษาฯ_2.txt
ซึ่งเราสามารถใช้ .split เพื่อแยกเอาแค่ประเภทข่าวออกมาได้
import pandas as pd
def get_news_type(path):
"""get news type from path to file"""
return path.split('/')[-1].split('_')[0]
news_type_df = pd.DataFrame([get_news_type(path) for path in paths],
columns=['news_type']).groupby('news_type').size().reset_index()
ใช้ news_type_df.sort_values(0, ascending=False) เพื่อเรียงลำดับจำนวนข่าวก็จะเห็นว่ามีข่าวเศรษฐกิจประมาณ 2659 ข่าว/
ข่าวจากทำเนียบรัฐบาล 2092 ข่าว/ ด้านสังคม 1338 ข่าว/ ความมั่นคง 817 ข่าว/ และ การศึกษา 802 ข่าว ส่วนข่าวประเภทอื่นๆได้แก่ ประเด็นเด่น กฎหมาย ทันข่าว …
จากนั้นเรามาลองอ่านเนื้อข่าวกัน เราเขียนฟังก์ชันเพื่ออ่านเนื้อข่าวตามข้างล่าง ตัดแค่บรรทัดที่มีคำว่า ที่มา นำหน้าถือเป็นโอเค
def read_text_file(path):
"""อ่านไฟล์จาก path ได้ได้รับ"""
f = open(path, 'r')
lines = f.readlines()
return [l for l in lines if not l.startswith('ที่มา')]
topics = ['ด้านการศึกษาฯ', 'ด้านเศรษฐกิจ', 'ด้านความมั่นคง',
'ข่าวทำเนียบรัฐบาล', 'ด้านสังคม', 'ด้านกฎหมายฯ'] # เลือกข่าวที่สนใจมา 6 ประเภทก่อน
df = pd.DataFrame(paths, columns=['file_path'])
df['text'] = df.file_path.map(read_text_file)
df['news_type'] = df.file_path.map(get_news_type)
df = df[df.news_type.map(lambda x: x in topics)] # เลือกเฉพาะข่าวที่สนใจ
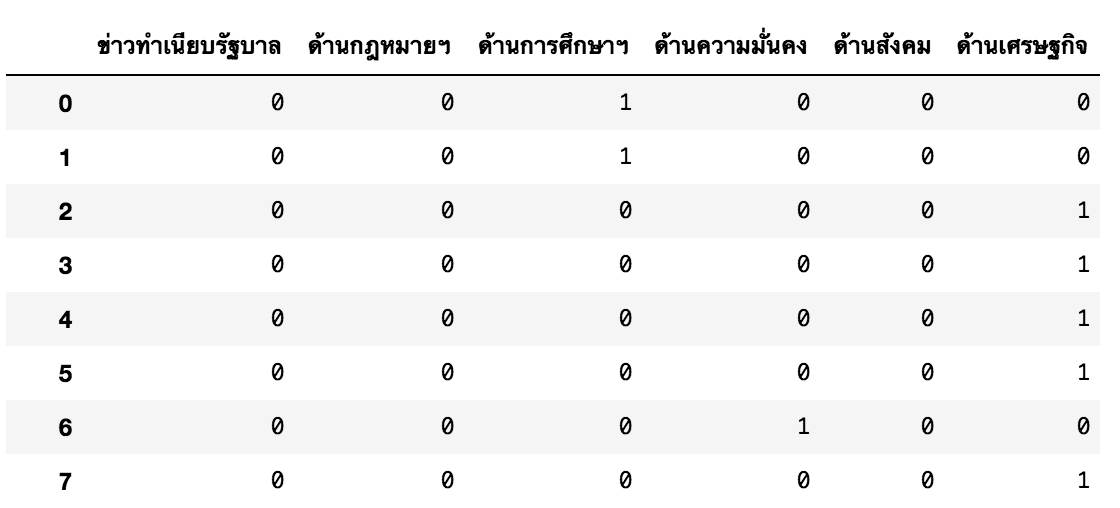
หน้าตาของ DataFrame จะเป็นตามด้านล่าง

จากนั้นเราจะใช้ deepcut ตัดคำจากเนื้อข่าวที่เราอ่านมา ซึ่งเก็บอยู่ใน column ที่ชื่อว่า text
ในที่นี้ข้อมูลทั้งหมดก็จะถูกแปลงไปอยู่ในรูปลิสต์ของคำในข่าว เก็บไว้ในตัวแปรชื่อ tokenized_texts
from itertools import chain
def tokenize_text_list(ls):
"""Tokenize list of text"""
return list(chain.from_iterable([deepcut.tokenize(l) for l in ls]))
tokenized_texts = df.text.map(tokenize_text_list) # รันนานหน่อยนะบรรทัดนี้
แปลงลิสต์ของข่าวเป็น Bag-of-words
อย่างที่กล่าวข้างต้น tokenized_text นี่จะเก็บเป็นลิสต์ของคำที่ตัดมาโดยใช้ deepcut เราสามารถเปลี่ยนให้เป็น bag of words เมทริกซ์ได้ไม่ยากมาก โค้ดเพื่อเปลี่ยนลิสต์ของคำเป็น bag of words สามารถทำได้ตามด้านล่างเลย
(แอบก็อปปี้โค้ดมาจาก deepcut
บรรทัดที่ 230 ถึง 252 ฮะ)
import scipy.sparse as sp
def text_to_bow(tokenized_text, vocabulary_):
"""ฟังก์ชันเพื่อแปลงลิสต์ของ tokenized text เป็น sparse matrix"""
n_doc = len(tokenized_text)
values, row_indices, col_indices = [], [], []
for r, tokens in enumerate(tokenized_text):
feature = {}
for token in tokens:
word_index = vocabulary_.get(token)
if word_index is not None:
if word_index not in feature.keys():
feature[word_index] = 1
else:
feature[word_index] += 1
for c, v in feature.items():
values.append(v)
row_indices.append(r)
col_indices.append(c)
# document-term matrix in sparse CSR format
X = sp.csr_matrix((values, (row_indices, col_indices)),
shape=(n_doc, len(vocabulary_)))
return X
vocabulary_ = {v: k for k, v in enumerate(set(chain.from_iterable(tokenized_texts)))}
X = text_to_bow(tokenized_texts, vocabulary_)
ง่ายๆก็คือเราหาคำที่ปรากฎทั้งหมดที่ก่อน แล้วเก็บไว้ใน dictionary เพื่อใช้แปลงศัพท์ที่เราเจอให้อยู่ในรูป index เช่น 'ลิง' จะถูกเปลี่ยนให้เป็นเลข 20 เป็นต้น
บางทีคำบางคำที่ใช้หรือปรากฎบ่อยๆในหลายๆข่าวจะมีน้ำหนักหรือความสำคัญน้อยกว่าคำที่เฉพาะสำหรับข่าวที่เราสนใจ
เราสามารถ weight ให้คำนั้นมีน้ำหนักน้อยลงโดยใช้ TfidfTransformer ได้ และก็ยังทำให้ dimension ของ text ลดลงได้โดยใช้ TruncatedSVD
นอกจากนี้เราต้องการจะทำนายประเภทของข่าวซึ่งตอนนี้เก็บเป็นประเภทข่าว เราจะต้องแปลงประเภทข่าวที่เรามีให้อยู่ในรูป binary (0,1) ก่อนโดยสามารถใช้คำสั่ง pd.get_dummies ของ pandas ได้
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.decomposition import TruncatedSVD
from sklearn.model_selection import train_test_split, cross_val_score
transformer = TfidfTransformer()
svd_model = TruncatedSVD(n_components=100,
algorithm='arpack', n_iter=100)
X_tfidf = transformer.fit_transform(X)
X_svd = svd_model.fit_transform(X_tfidf)
y = pd.get_dummies(df.news_type).as_matrix() # แปลงจากประเภทข่าวให้เป็นฟอร์แมต 0, 1 แทน
X_train, X_test, y_train, y_test = train_test_split(X_svd, y, stratify=y)
นำ Deepcut มาคัดข่าว
ก่อนอื่นเราต้องการดูว่าเราจะ predict ประเภทข่าวได้แม่นยำขนาดไหน วีธีเช็คความแม่นยำหรือ accuracy
ของโมเดลทำได้โดยการใช้ cross_val_score จาก library ชื่อ scikit learn ฮะ
เราจะใช้ for loop เพื่อเช็คว่าเราทำนายข่าวแต่ละประเภทได้แม่นยำขนาดไหน
cross_val_score รับ predictor ซึ่งเราจะใช้ Logistic Regression ในที่นี้ กับ input X_svd
และ output y แต่ละ column เข้าไป (ต้องใส่ข่าวทีละประเภทเข้าไป)
logist_model = LogisticRegression()
cv_scores = []
for c in range(y.shape[1]):
cv_scores.append(cross_val_score(logist_model, X_svd, y[:, c], cv=10, scoring='accuracy').mean())
news_type = pd.get_dummies(df.news_type).columns # ประเภทข่าวที่สนใจ
print(list(zip(news_type, cv_scores)))
[('ข่าวทำเนียบรัฐบาล', 0.9396227477900364),
('ด้านกฎหมายฯ', 0.9870547822708584),
('ด้านการศึกษาฯ', 0.9674521365359503),
('ด้านความมั่นคง', 0.9496678096700233),
('ด้านสังคม', 0.9443473736519051),
('ด้านเศรษฐกิจ', 0.9321212435287405)]
จะเห็นว่าเราสามารถทำนายข่าวได้ค่อนข้างแม่นยำเลยทีเดียวเกือบ 95 เปอร์เซ็นต์ในข่าวทุกประเภท ขนาดผมที่เขียนโพสต์ยังแยกไม่ออกเลยว่าข่าวไหนเป็นประเภทไหน ฮ่าๆ
สำหรับผู้อ่าน ลองเปลี่ยน scoring เป็นอย่างอื่น เช่น precision หรือ recall ดู หรือลองเปลี่ยน cv
จาก 10 folds เป็น 5 folds หรือ 3 folds แล้วลองดูว่าสกอร์เปลี่ยนไปยังไงบ้างก็ได้
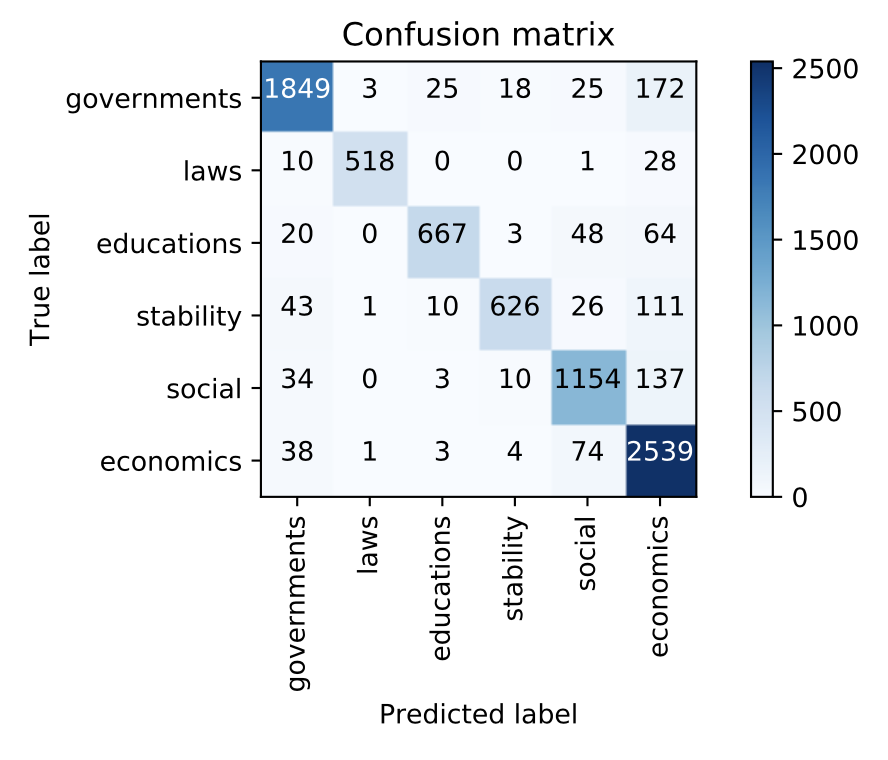
ยิ่งไปกว่านั้นเราสามารถดูได้ด้วยว่าส่วนมากเนี่ย เรา predict ข่าวประเภทไหนติดเป็นข่าวประเภทไหน โดยใช้ confusion matrix
y_pred = np.argmax(np.vstack([model.predict_proba(X_svd)[:, 1] for model in logist_models]).T, axis=1)
y_pred = np.array([news_type[yi] for yi in y_pred])
y_true = df.news_type.as_matrix()
C = confusion_matrix(y_true, y_pred) # confusion matrix
แต่ละแถวคือ True label และแต่ละหลักคือ Predicted label เราจะเห็นได้ว่าส่วนมากเราจะเดาผิดว่าเป็นข่าวเศรษฐกิจซะส่วนใหญ่ ถ้า predict ถูกทั้งหมดทุกอย่างต้องอยู่ในแนวแทยงมุมนะจ้ะ
เทรนโมเดลและลองใส่ข่าวเข้าไปเอง
เราสามารถเทรน Logistic Regression เพื่อ predict ว่าข่าวที่ใส่เข้าไปเป็นข่าวประเภทไหน เราจะเทรนทั้งหมด 6 โมเดล โดยแต่ละโมเดลจะใช้ predict ข่าวแต่ละประเภทฮะ
logist_models = []
for c in range(y.shape[1]):
logist_model = LogisticRegression()
logist_model.fit(X_train, y_train[:, c])
logist_models.append(logist_model)
ยกตัวอย่างถ้าเราจะใส่ข่าวใหม่เข้าไป เพื่อดูว่าข่าวนี้จะเป็นข่าวประเภทไหน (ในที่นี้เราจะลองใส่ข่าวเศรษฐกิจเข้าไปฮะ)
text = 'วันศุกร์ที่ 4 สิงหาคม 2560\n', 'ASEAN-India Expo and Forum การเชื่อมโยงอาเซียน-อินเดียครั้งสำคัญ สู่การเติบโตและเสถียรภาพของเศรษฐกิจโลก ฯพณฯ นายกรัฐมนตรี พลเอกประยุทธ์ จันทร์โอชา เป็นประธานในพิธีเปิด “ASEAN-India Expo and Forum” วาระทางเศรษฐกิจแห่งปี ซึ่งมีรัฐบาลไทยโดยกระทรวงพาณิชย์เป็นเจ้าภาพ จับมือกับหน่วยงานพันธมิตร และอีก 9 ประเทศสมาชิกอาเซียนรวมทั้งประเทศอินเดีย จัดเวทีพบปะครั้งใหญ่ระหว่างผู้แทนระดับสูงภาครัฐและภาคเอกชนจากทั้งสองฝ่าย ...'
tokenized_text = deepcut.tokenize(text)
x = text_to_bow([tokenized_text], vocabulary_)
x_tfidf = transformer.transform(x)
x_svd = svd_model.transform(x_tfidf)
pred = [model.predict_proba(x_svd.reshape(-1, 1).T).ravel()[1] for model in logist_models]
print(list(zip(news_type, pred)))
ผลที่ได้คือตามข้างล่างเลย
[('ข่าวทำเนียบรัฐบาล', 0.21981501890431207),
('ด้านกฎหมายฯ', 0.011156963634264003),
('ด้านการศึกษาฯ', 0.05411054878438172),
('ด้านความมั่นคง', 0.05725187418015803),
('ด้านสังคม', 0.07433082039376637),
('ด้านเศรษฐกิจ', 0.4959308735887242)] # น่าจะเป็นข่าวเศรษฐกิจมากที่สุด probability = 0.49
ความน่าจะเป็นที่ข่าวนี้เป็นข่าวด้านเศรษฐกิจสูงที่สุดเลย ตรงเป๊ะครับ :)
(แถม) ลองใช้ word vector จาก fastText มาลองคัดข่าว
เราจะมาลองใช้ฟีเจอร์ที่คนทั่วไปใช้กันอย่าง word vector เข้ามาช่วยบ้าง เพื่อดูว่าเราจะได้ความแม่นยำของ
การทำนายสูงขึ้นขนาดไหน ในที่นี้เราจะนำ pre-trained vectors จาก Facebook fastText
มาลองคัดข่าวดูหน่อยซิ (ต้อง install fastText ตาม repository ก่อน แล้วก็โหลด wiki.th.bin จาก repository มานะ)
และถ้า fastText ยังทำงานไม่ดีพอ เราก็ยังมีตัวเลือกอย่างเช่น thai2vec
ใช้ลองใช้กันอีกด้วย
วิธีการคัดข่าวหรือคัดประเภทเอกสารโดยใช้ word vector ที่คนใช้มากๆคือการนำ deep learning เข้ามาช่วย แต่ในที่นี้เราจะลองแบบง่ายๆคือการเฉลี่ย word vector ของคำทุกคำในข่าวก่อนว่าจะทำได้ดีขนาดไหน
จริงๆแล้ว โค้ดข้างล่างเราไม่ได้เฉลี่ยซะทีเดียว เราใช้เทคนิคจากเปเปอร์ ICLR 2017, A Simple but Tough-to-Beat Baseline for Sentence Embeddings ซึ่งใส่น้ำหนักให้กับ word vector ก่อนเฉลี่ยตามความน่าจะเป็นของการเกิดของคำ จากนั้นเราก็หักออกด้วย first component Eigenvector ฮะ
from fastText import load_model
from itertools import chain
from collections import Counter
from numpy.linalg import eig
thai_model = load_model('/wiki.th/wiki.th.bin')
word_appearance = Counter(chain.from_iterable(df.tokenized_text_clean))
word_df = pd.DataFrame(list(word_appearance.items()), columns=['word', 'occurence'])
word_df['p_occurence'] = word_df.occurence / word_df.occurence.sum()
p_dict = {r['word']: r['p_occurence'] for _, r in word_df.iterrows()}
def get_sentence_vector(ls, a=10e-4):
"""Average word vector for given list of words using fastText
ref: A Simple but Tough-to-Beat Baseline for Sentence Embeddings, ICLR 2017
https://openreview.net/pdf?id=SyK00v5xx
"""
wvs = []
for w in ls:
wv = thai_model.get_word_vector(w)
if w is not None:
wvs.append([wv, p_dict[w]])
wvs = np.array(wvs)
return np.mean(wvs[:, 0] * (a / (a + wvs[:, 1])), axis=0)
X = np.vstack(df.tokenized_text.map(get_sentence_vector))
eig_val, eig_vec = eig(X.T.dot(X))
u = eig_vec[:, 0].reshape(-1, 1).T
X_sent = np.vstack([x - u.T.dot(u).dot(x) for x in X])
y = pd.get_dummies(df.news_type).as_matrix()
ถ้าลองใช้ LogisticRegression มาเทรนตามเดิม จะได้ความแม่นยำประมาณนี้
[('ข่าวทำเนียบรัฐบาล', 0.8791321786744998),
('ด้านกฎหมายฯ', 0.9696326321735704),
('ด้านการศึกษาฯ', 0.9424088596016322),
('ด้านความมั่นคง', 0.9021179281713374),
('ด้านสังคม', 0.9069586440039169),
('ด้านเศรษฐกิจ', 0.8617069956188275)]
อ้าแย่จัง ยังสู้ไม่เท่าเทคนิค bag of words ที่เราพูดกันมาก่อนหน้า แต่ก็ได้ความแม่นยำดีมากๆ แต่อย่าลืมนึกไปว่า ถ้าเราเอาไปคัดเอกสารที่เราไม่เคยเห็นมาก่อน การใช้ word vector นั้นมีข้อดีคือเค้าเก็บเวกเตอร์ที่เทรนมาจาก Wikipedia และ เอกสารอีกมากมายซึ่งทำให้เราไม่ต้องขยาย bag of words ออกไปจนใหญ่มากๆนะ นอกจากนี้เรายังเพิ่มความแม่นยำโดยการนำเทคนิค deep learning มาช่วยในการคัดข่าวจากการดู sequence ของ word vectors ได้อีกด้วย
อารัมภบท
ในโพสต์นี้เราเอา data จากข่าวของรัฐบาลมาลองแยกว่าข่าวไหนเป็นข่าวประเภทอะไรบ้างโดยใช้เทคนิค bag of words ไม่น่าเชื่อว่าเราสามารถแบ่งประเภทข่าวได้ค่อนข้างดีเลยโดยใช้แค่ Logistic Regression classifier เท่านั้น
ในโพสต์หน้าๆเราจะมาลองใช้ Deep Learning กับ fastText โดยเราจะใช้เวกเตอร์ของคำ หรือว่า word embedding เข้ามาช่วยด้วย
ถ้าใครสนใจก็ลองไปเขียนเล่นกันดูก่อนได้เลยว่าจะคัดประเภทข่าวได้ดีขนาดไหน