![[ML] Bagging หรือ Boosting คืออะไร ทำงานอย่างไร?](https://tupleblog.github.io/images/post/baggingboosting/schematic.png)
ช่วงสัปดาห์ที่ผ่านมาพี่ตั๋นในทีม tupleblog ทักมาในกลุ่มถามว่า Random Forest กับ XGBoost ใช้งานต่างกันยังไง ถ้าระดับพี่ตั๋นถามแล้ว คนอื่นๆก็น่าจะถามเช่นเดียวกัน เราเลยตั้งใจว่าจะเขียนบล็อกสั้นๆไว้อธิบายเพราะหลายๆคนน่าจะมีคำถามใกล้เคียงกัน แล้วก็เผื่อกลับมาอ่านเองด้วยในอนาคต
อารัมภบท
เราอาจจะคุ้นเคยการทำการสำรวจในที่สาธารณะ เช่น ให้คนทำนายจำนวนประชากรในประเทศไทย หรือสำรวจว่าพรรคการเมืองไหนจะชนะการเลือกตั้ง ถ้าเราสุ่มถามแค่ 1-2 คน ก็อาจจะไม่ได้คำตอบที่ใกล้เคียงความเป็นจริงมากเท่าไหร่ แต่ไม่น่าเชื่อว่าถ้าเราถามคนเยอะขึ้นเรื่อยๆแล้วเอาคำตอบมาเฉลี่ยกัน คำตอบนั้นส่วนมากจะเข้าใกล้ความเป็นจริงมากขึ้นเรื่อยๆ หรือที่เค้าเรียกว่า Wisdom of the crowd นี่เอง
ใน Machine Learning ก็มีการนำคอนเซ็ปต์คล้ายๆกันแบบ Wisdom of the crowd มาประยุกต์ใช้กับการทำนายข้อมูลเช่นกัน เค้าเรียกกันว่่า Ensemble technique หรือการนำ classifier หลายๆตัวมารวมกันนั่นเอง จริงๆแล้วคนส่วนมากก็ใช้เทคนิคเหล่านี้กันอย่างแพร่หลายเช่นใน Kaggle Competition จนบางทีลืมว่าแต่ละวิธีมีการทำงานอย่างไร
วันนี้เราจะมาพูดถึงเทคนิค Ensemble ใน Machine Learning ที่คนใช้กันบ่อยมากๆสองวิธีด้วยกัน ได้แก่
- Bagging (ย่อมาจาก Bootstrap Aggregation) ซึ่งเป็นพื้นฐานของ Random Forest Classifier ใน
scikit-learnlibrary - Boosting ซึ่งเป็นพื้นฐานของ AdaBoost หรือ Gradient Boosting ในไลบรารี่เช่น
XGBoostและLightGBM
มาถึงจุดนี้ หลายๆคนคงจะคุ้นเคยกับชื่อ Random Forest และ Gradient Boosting กัน เดี๋ยวเราจะไปดูกันว่าแต่ละแบบมันทำงานต่างกันยังไง
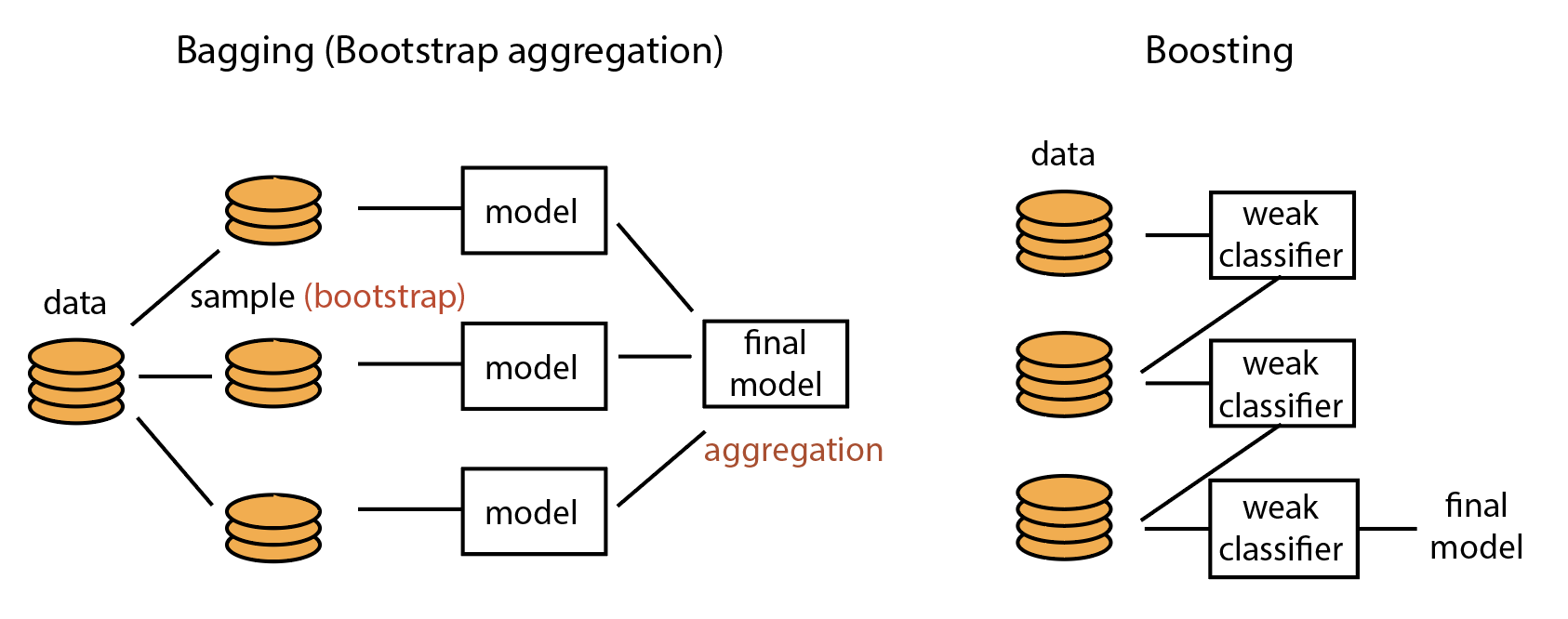
Bagging (Bootstrap Aggregation)
อย่างที่เรากล่าวไปข้างต้น Bagging เป็นพื้นฐานของอัลกอริทีมที่คนใช้กันบ่อยมากๆได้แก่ Random Forest Classifier นั่นเอง คำว่า Bagging นั้นย่อมาจาก “bootstrap aggregation” ซึ่งถ้ามีใครเคยเรียนวิชาสถิติจะรู้ว่า boostrap คือการสุ่มข้อมูลมาจากข้อมูลประชากร เพื่อใช้คำนวณค่าทางสถิติของประชากรกลุ่มเล็กๆที่เราสุ่มออกมา และ aggregation ก็คือการเอารวมกัน ดังนั้น Bagging หรือ boostrap aggregation ก็คือการสุ่มตัวอย่างข้อมูลออกมาแล้วสร้าง classifier ขึ้นมานี่เอง สำหรับวิธีการสุ่มข้อมูลออกมา เราใช้วิธีสุ่มแบบแทนที่ (random with replacement) ซึ่งหมายความว่าข้อมูลที่เรามียังอยู่เหมือนเดิม ไม่ได้ลดลงหลังจากการสุ่ม เราสามารถสุ่มข้อมูลหลายๆรอบเพื่อให้ได้ classifier หลายๆตัว แล้วเวลาทำนายก็ใช้ classifiers ทุกตัวที่เราสร้างขึ้นมาเพื่อทำนายชุดข้อมูลใหม่ที่เจอ การทำนายก็มีได้หลายแบบได้แก่การเฉลี่ยหรือการโหวตก็ได้ แล้วแต่ว่าเราทำนายความน่าจะเป็นหรือทำนายประเภทข้อมูล
บางคนจะใช้เทคนิคการจำว่า bagging คือการสุ้มข้อมูลมาเป็นถุงๆแล้วสร้างโมเดลจากถุงข้อมูลที่หยิบออกมาก็ได้
นอกจากสุ่มข้อมูลแล้วเรายังสามารถสุ่ม features ของข้อมูลได้อีกด้วย วิธีการสุ่มข้อมูลนี้ทำให้เราได้โมเดลหลายๆตัวมาช่วยกันทำนาย ทำให้เราสามารถลดแนวโน้มที่โมเดลจะ overfit ข้อมูลที่เรามีอีกทางนึง เช่นข้อมูลมี 20 features (20 columns) เราก็สามารถสุ่มข้อมูลออกมาโดยใช้ features เพียงครึ่งเดียวก็ได้
ลองนึกดูว่าถ้าเราทำนายผลของข้อมูลด้วย decision tree เพียง 1 โมเดล โอากาสที่เราจะ overfit มีสูงมากๆเนื่องจากโมเดลนี้เทรนมาเพื่อทำนายข้อมูลที่เราใส่เข้าไป แต่อาจจะไม่สำเร็จสำหรับข้อมูลอื่นๆก็ได้ การนำ decision tree มารวมกันเป็นป่า หรือ Random Forest สามารถช่วยลดโอกาสที่เราจะ overfit ได้นั่นเอง
Boosting
ส่วน Boosting นั้น วิธีคิดจะไม่ค่อยเหมือนกับ Bagging ซักเท่าไหร่ Boosting คือการนำ weak classifier หรือ classifier ที่มีความแม่นยำต่ำมา ทำนายข้อมูลที่เรามี จากนั้นเราจะให้ weak classifier ตัวใหม่มาแก้ไข error ที่เรามี โดยผลรวมของ classifier จะเกิดเป็น classifier ใหม่ขึ้นมา เราจะทำแบบนี้ไปเรื่อยๆจนได้โมเดลที่ดีที่สุดจากผลรวมของ classifier
ถ้าให้มองภาพรวมการทำงานของ Boosting ก็เหมือนการทำงานเป็นทีมนั่นเอง โดยการเอา classifier ที่ไม่ได้ดีมากมารวมกันจนทำนายข้อมูลที่ซับซ้อนมากๆได้
ข้อเสียของการใช้ boosting ก็คือเราต้องรันหลายๆครั้งและเป็นลำดับกว่าจะได้โมเดลที่ต้องการ ต่างจาก Bagging ที่สามาถสุ่มข้อมูลได้แล้วเทรนโมเดลได้พร้อมๆกันเลย
แต่ความเจ๋งของ library เช่น XGBoost นั้น เราจะสามารถเลือกชนิดของ weak learner หรือ weak classifier นี้ได้ด้วย ไม่ว่าจะเป็นแบบต้นไม้ (tree) หรือแบบเส้นตรง (linear) และในหลายๆครั้งนั้นเทคนิค boosting สามารถทำนายข้อมูลที่มีความซับซ้อนมากๆได้มากกว่าการใช้ bagging
แล้วอะไรดีกว่ากัน?
จริงๆแล้วทั้งสองเทคนิคเป็นการช่วยทำให้เราได้โมเดลที่มีความแม่นยำและความเสถียรต่อการเจอข้อมูลใหม่ๆ แต่ทั้งสองวิธีก็มีความดีแตกต่างกันไป
ถ้าเราเทรนโมเดลเดียวเช่น decision tree แล้วยัง overfit ข้อมูลอยู่ (variance สูง) การใช้ Bagging ค่อนข้างจะตรงจุดที่สุด เนื่องจากการสร้างโมเดลหลายๆอันมาเทรนชุดข้อมูลแบบสุ่ม ทำให้เราไม่ overfit ข้อมูลมากจนเกินไป
ส่วนถ้าเราฟิตโมเดลแล้วยังไม่ได้ความแม่นยำเท่าที่ควร และเราต้องการความแม่นยำเพิ่มขึ้นมากๆ การใช้เทคนิคเช่น bagging อาจจะไม่ช่วยมากนัก แต่ว่า boosting สามารถทำให้เราสร้าง predictor หรือ classifier ที่มีความแม่นยำสูงมากๆได้
Bagging ช่วยแก้ปัญหา overfitting ส่วน Boosting ช่วยแก้ปัญหาความแม่นยำต่ำ (bias)
ทิ้งท้าย
สำหรับการนำไปใช้จริง ทั้งสองเทคนิคมีความแม่นยำสูงต่ำต่างกันไปขึ้นอยู่กับข้อมูลที่เรามี โดยสำหรับภาษาอย่าง Python ก็มีโค้ดใน Scikit Learn และ XGBoost ซึ่งมีโค้ดของ Random Forest และ XGBoost ไว้เรียบร้อย เราไม่ต้องเขียนเองเลยจนบางครั้งเราลืมว่าแต่ละเทคนิคทำงานต่างกันอย่างไร ผู้เขียนหวังว่าคนที่อ่านโพสต์นี้จะเข้าใจเบื้องลึกเบื้องหลังของการทำงานของโมเดลทั้งสองแบบมากขึ้นเวลานำไปใช้งานครับ
สำหรับใครที่อยากอ่านเพิ่มเติม ยังมีอีกหลายๆเทคนิคที่คนแนะนำใช้กันอย่างเช่น Stacking ซึ่งเราไม่ได้อธิบายในโพสต์นี้ฮะ :)