สำหรับโพสต์ที่แล้ว เราได้ลองใช้ฟังก์ชันง่ายๆใน Python เพื่อช่วยในการวิเคราะห์ไลน์แชทกันไป ในโพสต์นี้เราจะมาลองเขียน Python snippet เพื่อใช้วิเคราะห์ news articles กันบ้าง ต้องบอกไว้ก่อนว่าเราไม่ได้ลองโหลดบทความมามากมาย แต่หวังว่าผู้อ่านจะได้เรียนรู้ library หลายๆอย่างบน Python และสามารถ เอามาใช้งานได้ในอนาคต เพื่อว่าหลังจากอ่านโพสต์นี้ ผู้อ่านจะเอาไปต่อยอดได้ง่ายขึ้น
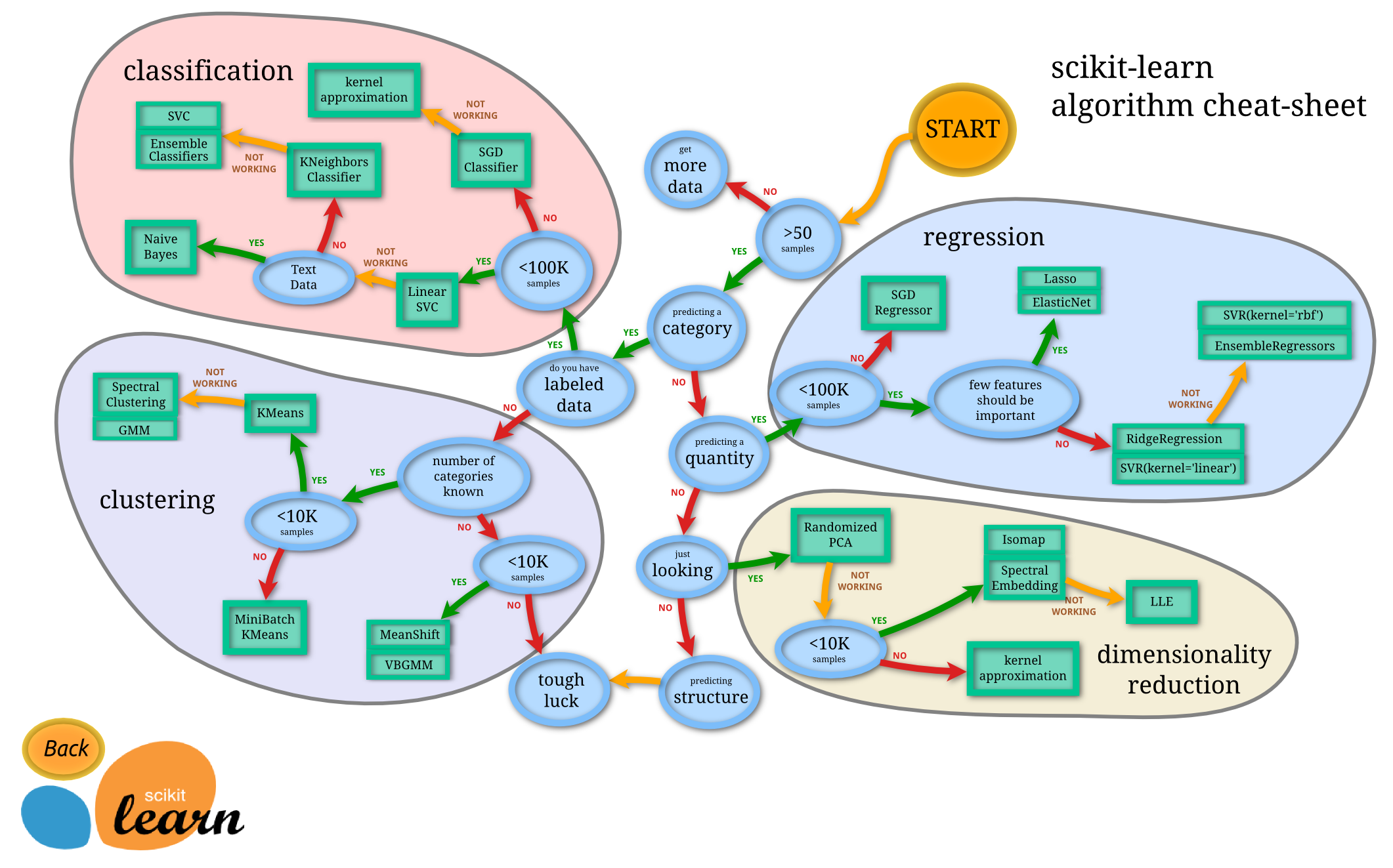
ก่อนเราจะลุยไปถึงโค้ดกันนั้น เรามาดูกันก่อนว่า tools หรือ library ที่เราจะใช้กันวันนี้มีอะไรบ้างตามลำดับ
- newspaper ใช้ในการดาวน์โหลดข่าวและลิงค์ของข่าวในหน้าหลัก
- BeautifulSoup ใช้ในการ scrape website หรือดึงข้อมูลมากจากเว็บไซต์นั่นเอง
- scikit-learn สำหรับ machine learning algorithm สำหรับโพสต์นี้เราจะใช้ Principal component analysis เพื่อลดจำนวนมิติของเวกเตอร์ของคำศัพท์ที่อยู่ในบทความ (dimensionality reduction) ซึ่งทำให้เราพล็อตกราฟออกมาสวยงาม ไม่ยุ่งเหยิง
- bokeh เป็น plotting library คล้ายกับ
matplotlibแต่สำหรับโพสต์นี้ เราต้องการเขียน interactive plot สำหรับการพล็อต เราเลยเลือกใช้bokehlibrary
สำหรับขั้นตอนของการเขียนโปรเจกต์ เราจะแบ่งเป็นสามขั้นตอนหลักๆดังต่อไปนี้
- เก็บข้อมูล (collect the data)
- ประมวลผล (เพื่อแปลง text จากข่าวให้เป็นเมกทริกซ์ที่เราสามารถพล็อตได้)
- พล็อต (visualization)
สิ่งที่เราจะเขียนในโพสต์นี้เป็นเพียง 1 กิ่งก้านของ “How to learn Machine Learning Roadmap in 6 months”
ที่แนะนำโดย scikit-learn เท่านั้น ไว้โพสต์หน้าๆ เราจะมาหาอะไรทำสนุกๆต่อ แต่ตอนนี้เรามาเริ่มกันเลยแล้วกัน
1. เก็บข้อมูล
ในกระบวนการทั้งหมดที่กล่าวมาข้างต้น การเก็บข้อมูลน่าจะเป็นกระบวนการที่ยากที่สุดแล้วก็เป็นได้
ในที่นี้เราใช้ไลบรารี่ชื่อ newspaper ไลบรารี่นี้มีคำสั่งที่ชื่อว่า build เพื่อให้เราเก็บลิงค์ทั้งหมดบนเพจนั้นๆได้
หลังจากเราโหลดลิงค์จากหน้าแรกมาแล้ว จะสามารถใช้คำสั่ง download เพื่อโหลดเนื้อหาข่าวของแต่ละบทความได้
เราเริ่มด้วยเว็บไซต์โปรดของเราเลย Wired.com
import newspaper
from newspaper import Article
wired_paper = newspaper.build('http://www.wired.com')
wired_urls = [u for u in wired_paper.article_urls() if 'https://www.wired.com/' in u]
wired_articles = []
for i, wired_url in enumerate(wired_urls):
wired_article = Article(wired_url)
wired_articles.append(wired_article)
for w in wired_articles:
w.download() # load all articles
สำหรับอีกเพจที่เราชอบมากก็คือ Engadget แต่เนื่องจากว่าเราไม่สามารถใช้ฟังค์ชัน download
เพื่อโหลดเนื้อหาข่าวหลังจากเก็บแต่ละ Article มาได้ ก็เลยต้องใช้ BeautifulSoup เพื่อโหลดเนื้อหาข่าวจาก
Engadget แทน หน้าตาของโค้ดเป็นตามด้านล่าง
import requests
from bs4 import BeautifulSoup
engadget_paper = newspaper.build('http://www.engadget.com/')
engadget_urls = [u for u in engadget_paper.article_urls() if 'video' not in u and 'tumblr' not in u]
engadget_contents = []
for url in engadget_urls:
r = requests.get(url)
engadget_contents.append([url, r.text])
r.text ในที่นี้คือ HTML ทั้งหมดจากแต่ละลิงค์เพจที่เราเก็บมาได้ เราต้องเขียนโค้ด BeautifulSoup
เพิ่มเติมเล็กน้อยเพื่อเก็บแท็กจากข่าว หัวข้อข่าว และเนื้อหาข่าว
def get_engadget_news_from_content(content):
soup = BeautifulSoup(content, "lxml")
title = []
tags = []
for s in soup.find_all('meta'):
if s.get('property') == 'og:title':
title = s.get('content', '')
elif s.get('name') == 'tags':
tags.append(s.get('content'))
body_text = ' '.join([p.text for p in soup.find_all('p') if p.get('class') is None])
return {'title': title,
'tag': ';'.join(tags),
'text': body_text}
หลังจากเราได้ข่าวจากทั้งสองแหล่งแล้ว แปลงเป็น dataframe และต่อ dataframe เข้าไปด้วยกัน
import pandas as pd
engadget_df.loc[:, 'source'] = 'engadget'
wired_df.loc[:, 'source'] = 'wired'
tech_news_df = pd.concat((wired_df, engadget_df)) # ต่อ dataframe เข้าด้วยกัน
จากตรงนี้ ใครขี้เกียจโหลดข่าวด้วยตัวเอง เราได้แปะ CSV (comma separated) file มาให้ด้วยที่
2. ประมวลผลข่าวที่ดาวน์โหลดมา
หลังจากเราได้ข่าวมาแล้วจากทั้งสองแหล่ง สิ่งที่เราจะทำถัดไปคือเราจะเก็บเฉพาะหัวข้อข่าวและ 3 ย่อหน้าแรก
def sample_paragraph(text):
paragraph = ' '.join([a for a in text.split('\n') if a.strip() != ''][0:4])
return paragraph
text_preproc = (tech_news_df.title + ' ' + tech_news_df.text.map(sample_paragraph)).map(lambda x: x.lower())
หลังจากนั้นใช้ TfidfVectorizer และ PCA จาก scikit-learn ไลบรารี่เพื่อแปลงข่าวทั้งหมดที่เรามีให้เหลือ
2 dimensions (เดี๋ยวว่างๆแล้วเราจะมาเขียนอธิบายเพิ่มให้อีกทีว่ามันคืออะไร)
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import PCA
tfidf_model = TfidfVectorizer(ngram_range=(1,2), max_df=0.8, min_df=1)
X = tfidf_model.fit_transform(text_preproc)
pca_model = PCA(n_components=2, whiten=True)
X_pca = pca_model.fit_transform(X.toarray())
X_pca ของเรามีขนาดเท่ากับ [n_article x 2] หรือเท่ากับ [150 x 2] นั่นเอง
แต่ละแถวของ X_pca คือข่าวที่ได้ถูกแปลงเป็นแค่ตัวเลขสองตัวเท่านั้น
3. พล็อต
ท้ายสุดแล้ว เราเหลือแค่พล็อตข้อมูลที่เราประมวลผลมา ในที่นี้เราจะเลือกใช้ไลบรารี่ชื่อ bokeh เพื่อพล็อตข้อมูลที่เรามี
หน้าตาของพล็อตแบบนี้บางทีเรียกว่า Scatter plot นะเออ
from bokeh.plotting import figure, show, ColumnDataSource
from bokeh.models import HoverTool
source = ColumnDataSource(tech_news_df)
# ใช้สีส้มถ้าเป็น Engadget และสีฟ้าถ้าเป็น the Wired
colors = tech_news_df['source'].map(lambda x: '#42b3f4' if x == 'wired' else '#f4a041')
hover = HoverTool(
tooltips=[
("title", "@title"),
("url", "@url"),
("source", "@source")
]
)
p = figure(plot_width=500, plot_height=800,
tools=[hover],
x_axis_label='1st Principal component',
y_axis_label='2nd Principal component')
p.circle('x', 'y', size=8, source=source,
fill_color=colors, fill_alpha=0.6,
line_color=None)
show(p)
และนี่คือพล็อตแบบ interactive (เฉพาะบนคอมนะ)
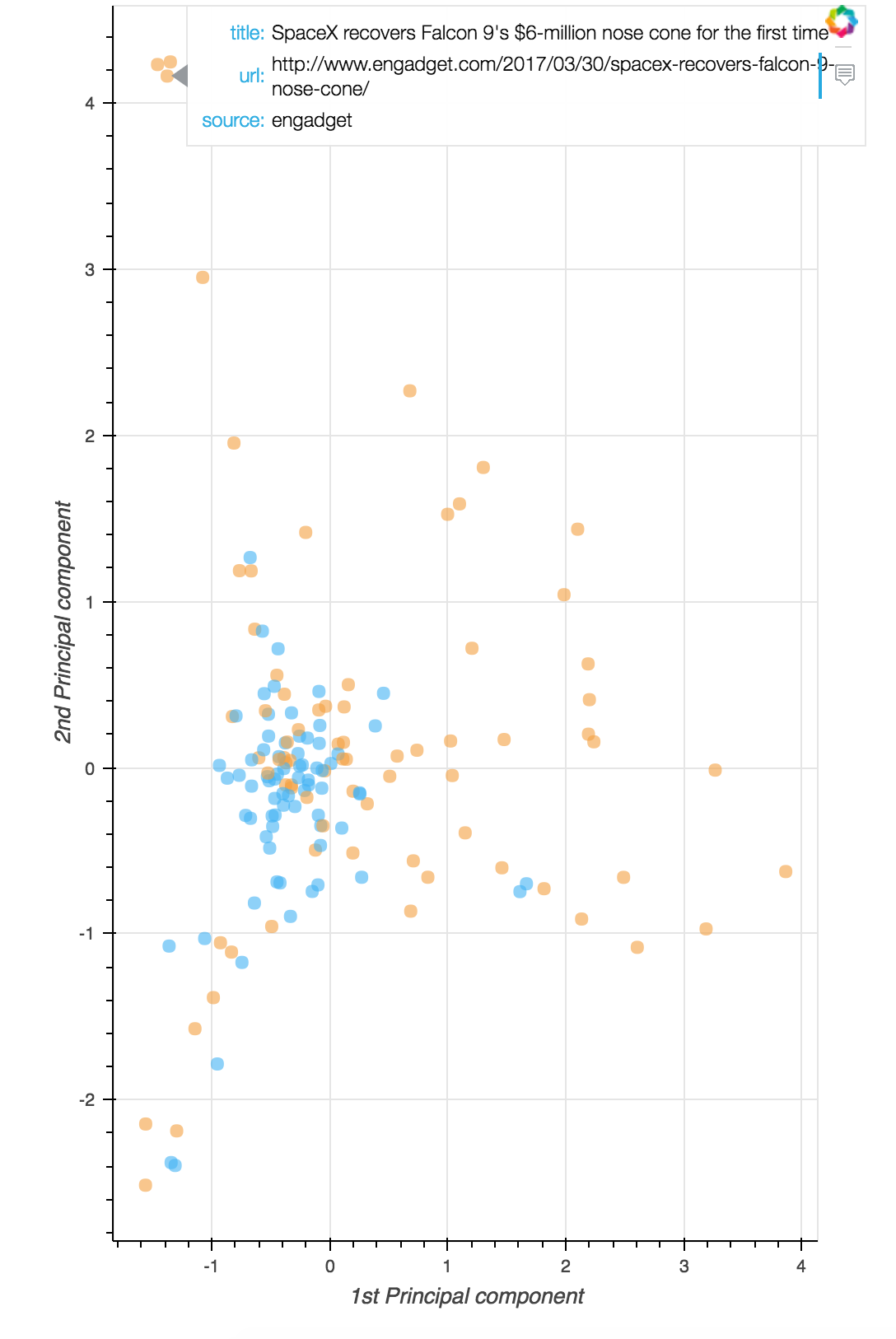
หลังจากนั้นเราก็จะได้พล็อตออกมา และเมื่อเราลากเมาส์ผ่านไปบนพล็อต จุดที่เราลากผ่านจะโชว์หัวข้อข่าว ลิงค์ไปยังข่าว และที่มาของข่าวให้เรา จุดข้างบนสามจุดนั้นคือเรื่องเกี่ยวกับ SpaceX ทั้งหมด กลุ่มข่าวด้านล่างนี่ เกี่ยวกับ Spotify และ Apple Music ส่วนข้างขวาเกี่ยวกับ Gadget เป็นหลัก
จะเห็นได้ว่าเพียงแค่ 150 ข่าว เราก็สามารถเริ่มจัดกลุ่มให้ข่าวพวกนี้ได้แล้ว ถ้ามีข่าวเพิ่มอีกมากๆ ก็ยังทำได้เช่นกัน :)
อารัมภบท
ออกจะยากไปหน่อยสำหรับโพสต์นี้ แต่ว่า สำหรับใครที่สนใจ data science เบื้องต้น ลองทำตามโพสต์นี้ ลอง download, clean data ซักหน่อย แล้วพล็อตข้อมูลที่เรามี เป็นแบบฝึกหัดที่ทำให้เราเล่นกับ data ได้อย่างสนุกขึ้นในอนาคตนะ