พื้นฐานก่อนจะเข้าสู่ Gradient Descent
ก่อนอื่นเลย ใครอยากลองอ่านเพิ่มเติมเป็นภาษาอังกฤษ ลองอ่านได้ที่
- An Introduction to Gradient Descent and Linear Regression เขียนโดย Matt Nedrich ซึ่งจะคล้ายกับที่เราจะพูดถึงต่อไปนี้
- The Zen of Gradient Descent เขียนโดย Moritz Hardt ซึ่งเค้าพูดถึง lecture ของ Ben Recht จาก University of California Berkeley ว่าด้วย gradient descent และให้ข้อคิดไว้ดีมากๆ
โพสต์นี้เราจะว่าด้วยเทคนิคสุดคลากสิกที่เป็นแก่นของการแก้เพื่อหาค่าที่เหมาะสมที่สุดให้กับฟังค์ชั่นหนึ่งๆ เกือบทุกอย่างทั้งในสายวิชา Optimization, Machine Learning ซึ่งฮิตกันมากๆในเวลานี้, Compress Sensing หรือการแก้ \( \ell_1 \)-regularization problem, Neural Network, Deep learning, Optimal Control, Adaptive filtering และอีกมากมาย ถ้าใครสนใจหัวข้อหรือวิชาที่พูดถึงเหล่านี้แล้ว วิชาทั้งหมดพวกนี้ต้องใช้อัลกอริทึม ที่ชื่อว่า “Gradient Descent” ทั้งสิ้น แค่มันอาจจะเปลี่ยนชื่อไม่เหมือนกันตามแต่ละวิชา ถ้าให้พูดถึงความสำคัญของ gradient descent ก็ต้องเรียกได้ว่าสำคัญมากเลยหล่ะ ถ้าใครที่อยากไปอยู่ในทีม Machine Learning หรือ Artificial Intelligence ที่พัฒนาอัลกอริทึมในยุคนี้ อัลกอริทึม gradient descent เรียกได้ว่าทุกคนต้องรู้จักเลยหล่ะ
ที่เราเขียนโพสต์นี้ขึ้นมาเพราะว่าเวลาเรียนหลายๆวิชาแล้ว เราจะไม่ค่อยได้ใส่ใจว่า จริงๆแล้วในเริ่มต้นของทุกวิชาที่กล่าวข้างบนล้วนอธิบายหลักการของ gradient descent ทั้งสิ้น เช่นใน Neural Network ก็ต้องหา gradient เพื่อใช้ในอัลกอริทึมที่เรียกว่า back propagation เพื่อหาพารามิเตอร์ของ Neural Network หรือใน Adaptive filter ก็ใช้ algorithm แบบเดียวกันใน least mean square algorithm
เราจะเริ่มโพสต์นี้จากแคลคูลัสพื้นฐานก่อน และจะยกตัวอย่าง Python code สำหรับการแก้สมการเหล่านี้ไปด้วยในตัว จากนั้นหลังจากอธิบายโค้ดเล็กน้อย เราก็จะข้ามไปถึง Stochastic Gradient Descent และสรุปทิ้งท้าย
หาจุดต่ำสุดหรือสูงสุดด้วยแคลคูลัส
ย้อนไปสมัยเด็กๆ (สมัยเรียนแคลคูลัส ม. 6 ที่สวนกุหลาบฯ) ถ้าสมมติอยากจะหาค่าของ \(x\) ที่ทำให้ \(f(x) = x^2 - 4x\) มีค่าต่ำที่สุด เราก็จะหา first derivative ของ \(f(x)\) นั่นคือ \(f’(x) = 2x - 4\) แล้วแก้สมการ \(f’(x) = 2x - 4 = 0\) ได้ค่าต่ำสุดของ \(x = 2\) นั่นเอง หรือถ้าจะจัดรูปสมการ \( f(x) = (x^2 - 4x + 4) - 4 = (x-2)^2 - 4 \) ก็จะรู้ว่าค่าต่ำที่สุดของ \(f(x) \) คือ -4 ที่ \(x = 2\)
โน้ต หลังจากนี้เราจะเรียก \( f(\cdot) \) ว่า \( J(\cdot) \) แทน หรือเรียกว่า Cost function ส่วน \(f’(\cdot)\) อาจเรียกว่า slope, derivative หรือว่า gradient ก็ได้ ตาม Machine learning text book จะใช้ notation ของ gradient ว่า \( \nabla J (\cdot)\) เพราะว่า \( x \) ที่ใส่เข้าไปอาจจะเป็นเวกเตอ์ \( \mathbf{x} \) ก็ได้ ซึ่งเราจะไม่ลงรายละเอียดของ notation มากในโพสต์นี้
ต่อไปเราจะมาลองดูกันว่า สมมติว่าเราอยากจะหาค่าต่ำสุดของ \( x \) ผ่านการใช้ algorithm นั้นต้องทำอย่างไร
Gradient Descent Algorithm
Gradient descent เป็นแก่นของการแก้เพื่อหาค่าที่เหมาะสมที่สุดให้กับฟังค์ชั่นหรือ Cost function หนึ่งๆ โดยการวนหาค่าที่ทำให้ cost (ในหนังสือส่วนมากมักเรียกว่า \( J \)) ต่ำสุด จากการคำนวณ slope ณ จุดที่เราอยู่แล้วพยายามเดินไปทางตรงข้ามกับ slope ถ้านึกภาพก็เหมือนเวลาเราเดินขึ้นเขา วิธีการเดินไปให้ถึงจุดสูงสุดคือเราไต่ขึ้นตามทางที่ชันขึ้นเพื่อไปถึงจุดสูงสุดนั่นเอง
อย่างที่กล่าวไว้ข้างต้น gradient descent คืออัลกอริทีมที่ใช้หาจุดต่ำสุดหรือสูงสุดของฟังค์ชั่น (ส่วนมากฟังค์ชั่นรูปกรวยคว่ำหรือ convex ใครสนใจก็ไปอ่านได้เพิ่มเติม ส่วนเด็กๆ ม. ปลาย ที่สนใจอยการู้เพิ่มเติมก็เลือกเรียนภาควิชาไฟฟ้าหรือคอมพิวเตอร์ก็ได้นะ) ถ้าเราลองดูกราฟรูปพาราโบลาหงายอย่างที่ยกตัวอย่างไปข้างต้น \(f(x) = x^2 - 4x\) ซึ่งมี gradient เท่ากับ \(f’(x) = \nabla f(x) = 2x - 4 \) เราสามารถเริ่มที่จุดใดๆก็ได้บนพาราโบลา เช่น \( x=10 \) จากนั้นการจะไปที่จุดต่ำสุด เราแค่หา slope ของ ณ จุดที่เรายืนอยู่แล้วพยายามเลื่อน \( x \) ไปในทิศทางตรงข้ามกับ slope และถ้าเราทำแบบเดียวกันหลายๆครั้ง \( x \) ก็จะลู่เข้าสู่จุดต่ำลงเรื่อยๆ และสิ้นสุดเมื่อถึงค่า \( x \) ที่ slope มีค่าเท่ากับศูนย์นั่นเอง ถ้า \( k \) คือ iteration หรือจำนวนครั้งที่เราวนหาค่า \( x \) แล้ว อัลกอริทึมที่หาจุดต่ำสุดของ \(f(x) = x^2 - 4x\) สามารถเขียนง่ายๆตามด้านล่าง
\[x_{k+1} = x_{k} - \alpha f'(x_{k})\]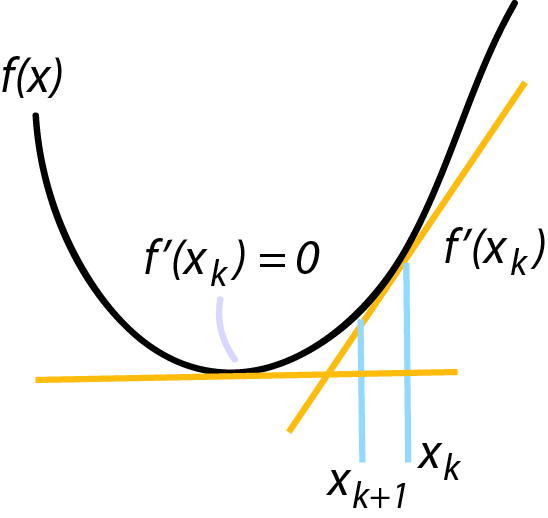
โดย \( \alpha \) ส่วนมากจะเรียกว่า learning rate ยิ่งมีค่ามากจะยิ่งลู่เข้าเร็ว แต่ถ้ามากเกินไป การอัพเดทครั้งถัดไปอาจจะทำให้ x มีค่ามากเกินไปจนลู่ออกไปถึงอนันต์ก็ได้ ส่วนมากจะเริ่มจากค่าต่ำๆก่อน แต่ถ้าลู่เข้าช้าเกินไป เราอาจจะปรับให้ \( \alpha \) มีค่ามากขึ้น แต่ไม่มากจนเกินไป
ใครมี Python ก็ลองแก้หาค่า \( x \) ที่ทำให้ \(f(x) = x^2 - 4x\) มีค่าต่ำที่สุดได้เลย ส่วนโค้ดสำหรับ Gradient Descent ง่ายๆเป็นไปตามข้างล่างเลย
x = 10 # initial x
n_iter = 1000 # number of iteration
alpha = 0.02
J = []
def compute_cost(x):
J = x ** 2 - 4 * x
return J
def compute_grad(x):
grad = 2 * x - 4
return grad
for i in range(n_iter):
x = x - alpha * compute_grad(x) # gradient descent
J.append(compute_cost(x)) # compute cost
print 'final x = %s' % x
print 'final cost = %s' % J[-1]
--------------------------------
final x = 2.0
final cost = -4.0
คำตอบของการใช้ gradient descent algorithm ได้เหมือนกับเราแก้โดยใช้มือเป๊ะเลย
หาสมการเส้นตรง โดยใช้ Gradient Descent
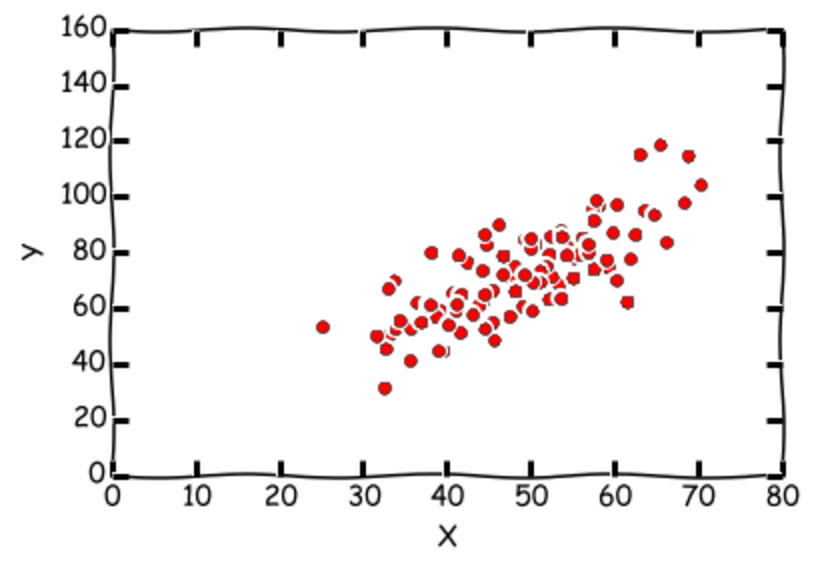
ไม่ใช่เพียงเท่านี้ สมมติเราจะแก้สมการ linear regression หรือง่ายๆคือการหาสมการเส้นตรงที่อธิบาย data ของเราได้ดีที่สุด ซึ่งเราต้องหา slope และจุดตัดแกนที่ทำให้ error ของเส้นตรงที่เราลากกับ data ทั้งหมดของเราให้น้อยที่สุด (นึกภาพเวลา Microsoft Excel พล้อตมาการเส้นตรงให้เราตอนที่ใส่ spread sheet เข้าไป ตอนนี้เราจะทำแบบเดียวกันกับ Excel) สมมติว่าเรามี data point ทั้งหมด m คู่ \( (x^{(1)}, y^{(1)}), (x^{(2)}, y^{(2)}), … (x^{(m)}, y^{(m)}) \) เช่น เราเก็บข้อมูลความสูงและน้ำหนักของคนที่เดินสยาม โดยในที่นี้ค่า x คือส่วนสูง ส่วนค่า y คือน้ำหนักเป็นต้น เราต้องการหา จุดตัดแกน \( (\theta_0) \) และ slope \( (\theta_1) \) (สมการเส้นตรงคือ \( (\theta_0 + \theta_1 x) \) นั่นเอง) ที่ทำให้ error ระหว่างทุกๆจุดกับเส้นตรงที่เราลากต่ำที่สุด เราจะเรียกพารามิเตอร์ทั้งสองว่า \( \Theta = [\theta_0, \theta_1]^T \) ส่วน Cost หรือฟังค์ชั่นที่เราต้องการหาจุดต่ำสุดก็คือความต่างของ error กับเส้นตรงที่เราประมาณ ซึ่งเขียนได้ดังนี้
\[J(\Theta) = J(\theta_0, \theta_1) = \cfrac{1}{2m} \sum_{i=1}^m ((\theta_0 + \theta_1 x^{(i)}) - y^{(i)})^2\]ต่อไปเรามาลองหา gradient ของ \(J( \Theta ) \) กัน
\[\nabla J (\Theta) = \begin{bmatrix} \cfrac{\partial J}{\partial \theta_0}\\ \cfrac{\partial J}{\partial \theta_1} \end{bmatrix} = \begin{bmatrix} \frac{1}{m} \sum_{i=1}^{m} ((\theta_0 + \theta_1 x^{(i)}) - y^{(i)}) \\ \frac{1}{m} \sum_{i=1}^{m} ((\theta_0 + \theta_1 x^{(i)}) - y^{(i)})x^{(i)} \end{bmatrix}\]วิธีการอัพเดทก็ทำแบบข้างบนเลย แค่ตอนนี้เราอัพเดท \( \Theta \) แทน
\[\Theta_{k+1} = \Theta_{k} - \alpha \nabla J(\Theta)\]ลองมาเขียน Gradient descent algorithm สำหรับการแก้สมการข้างบนนี้กันดู ใช้ตัวอยากจาก Github นี้ ลองโหลด data จาก ที่นี่ เลย ซึ่งถ้าเราพล้อตดู data จะเป็นประมาณข้างล่างนี้
import numpy as np
def compute_grad(X, y, theta):
m = len(X)
theta_grad = np.array([0, 0])
for i in range(m):
theta_grad[0] += (1./(m))*((theta[0] + theta[1]*X[i]) - y[i])
theta_grad[1] += (1./(m))*((theta[0] + theta[1]*X[i]) - y[i])*X[i]
return theta_grad
def compute_cost(X, y, theta):
m = len(X)
J = 0
for i in range(m):
J += (1./(2*m))*((theta[0] + theta[1]*X[i]) - y[i])**2
return J
data = np.genfromtxt("data.csv", delimiter=",") # read csv file (don't forget to download!)
X = data[:,0]
y = data[:,1]
J = [] # history of cost
theta = np.array([0, -1]) # intial theta
n_iter = 3000
for i in range(n_iter):
theta_grad = compute_grad(X, y, theta)
theta = theta - 0.0001*theta_grad
J.append(compute_cost(X, y, theta))
print 'final theta = %s' % theta
print 'final cost = %s' % J[-1]
--------------------------------
final theta = [ 0.0118 1.4984]
final cost = 56.7869030526
จากข้างบน ถ้าเราพล้อตเส้นตรงที่อธิบาย data ที่เรามีดีที่สุด เราก็จะพบว่าจุดตัดแกนมีค่าประมาณ 0.0118 และความชันหรือ slope มีค่าเท่ากับ 1.4984 นั่นเอง ลองไปดู gif file ว่าแต่ละ iteration เกิดอะไรขึ้นบ้าง ได้โดย คลิ้กที่นี่ เลย เรายังไม่ได้ลองเอา data ชุดเดียวกันไปใส่ใน Excel แต่คิดว่าก็จะได้ค่าเท่ากัน จากตอนนี้ เราสามารถแก้สมการ \( \lVert \Theta^T \mathbf{x} - y \rVert^2 \) โดยที่ \( \Theta \) อาจจะมีขนาดเกินกว่าแค่ \( \Theta = [\theta_1, \theta_2]^T \) ก็ได้ เช่น \( \Theta = [\theta_1, \theta_2, … \theta_m]^T \)
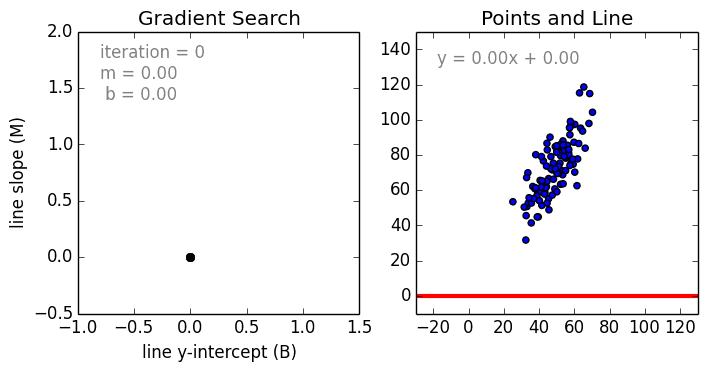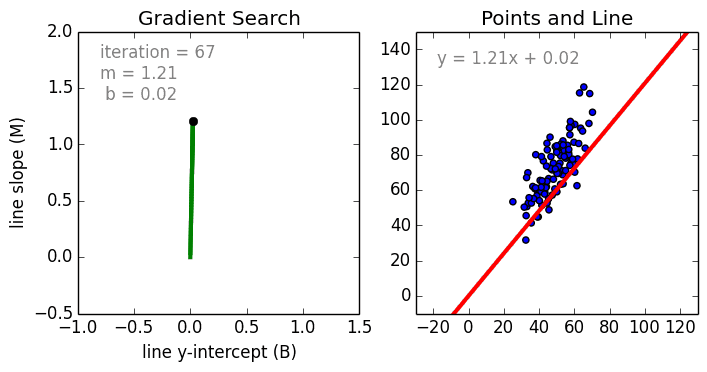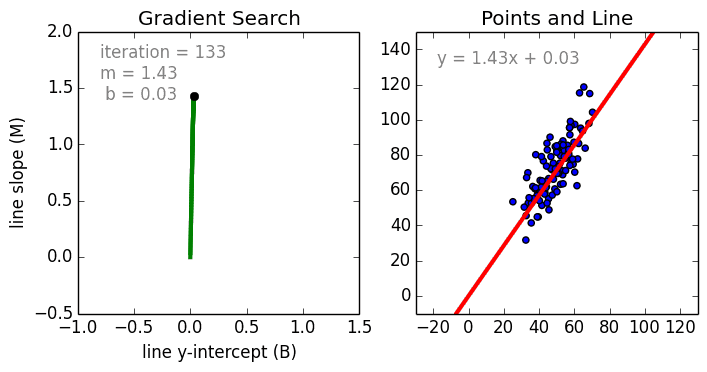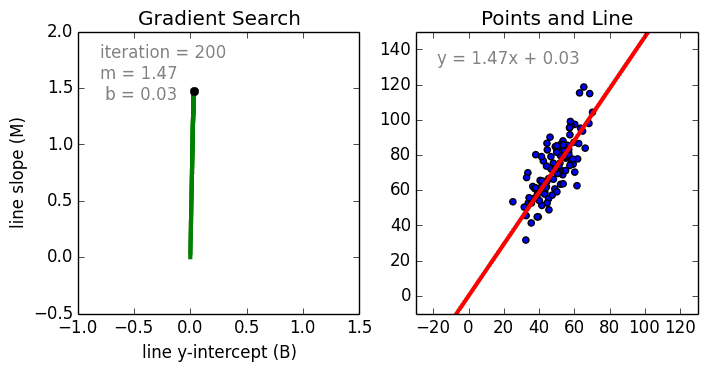{kind=link}
ว่าด้วย Stochastic Gradient Descent (SGD)
ลองนึกภาพว่าสมมติเรามี data เยอะมากๆ เช่น เรามีหนึ่งล้านคู่ของ \( (x^{(i)}, y^{(i)}) \) การที่จะคำนวณ gradient แต่ละครั้งนั้น เราต้องใช้ data ทั้งหมดเพื่อมาอัพเดทพารามิเตอร์ใหม่ซึ่งแน่นอนว่าใช้เวลามากกว่าแน่นอน สำหรับ Stochastic gradient descent ในแต่ละการคำนวณ gradient เราจะสุ่ม data เพียงบางส่วนเพื่อใช้อัพเดทเท่านั้น ไม่ได้ใช้ data ทั้งหมด โดยทฤษฎีได้พิสูจน์ว่าเราสามารถใช้ data เพียงไม่มากเพื่อใช้ในการอัพเดทพารามิเตอร์ในแต่ละครั้งหรือ iteration โดยไม่ต้องนำ data ทั้งหมดมาทีเดียวก็ได้ แต่ในที่สุดจะลู่เข้าสู่คำตอบใกล้เคียงกัน
และยิ่งในกรณีที่พารามิเตอร์ที่เราต้องการประมาณมีเยอะมากๆ เช่นใน Neural Network การใช้ Stochastic gradient descent สามารถลดปัญหาของการที่ optimization ติดอยู่ใน local minima ได้อีกด้วย
ตัวอย่างข้างล่างเราแค่สุ่ม data เพียง 20 ตัวเพื่อใช้ในการอัพเดทของเรา (ใช้ฟังค์ชันเดียวร่วมกับข้างบน) แต่สุดท้ายคำตอบที่ได้ มี cost น้อยกว่าที่เราใช้ gradient descent ปกติซะอีก และถ้าใครลองเขียนดูตามด้านล่าง จะเห็นได้ว่า SGD เร็วกว่าอีกด้วยหล่ะ
def sample(X, y, n_sample=20):
idx_sample = np.random.randint(m,size=n_sample)
return X[idx_sample], y[idx_sample]
J = [] # cost
theta = np.array([0, -1]) # intial theta
n_iter = 3000
for i in range(n_iter):
X_sample, y_sample = sample(X, y) # sample
theta_grad = compute_grad(X_sample, y_sample, theta)
theta = theta - 0.0001*theta_grad
J.append(compute_cost(X, y, theta))
print 'final theta = %s' % theta
print 'final cost = %s' % J[-1]
--------------------------------
final theta = [ 0.0656 1.4715]
final cost = 56.3702935651
ทฤษฎีทิ้งทาย
ที่กล่าวมาข้างต้นคือตัวอย่างของการใช้ Gradient descent ซึ่ง ถึงตรงนี้หวังว่าผู้อ่านจะเห็นภาพมากขึ้นแล้ว สำหรับหัวข้อนี้เราจะทิ้งท้ายให้คนที่ชอบทฤษฎีเท่านั้น ถ้าใครที่เห็นว่ายากเกินไปก็ข้ามไปที่สรุปได้เลย
ถ้าเราสมมิตว่า cost function \( f \) เป็นฟังค์ชัน convex หรือพูดให้เข้าใจง่ายๆคือมีรูปเป็นพาราโบลาหงาย (หลายคนคงสงสัยว่า เห้ย แล้วทุกปัญหาเขียนเป็น convex function ได้หมดเลยหรอ คำตอบก็คือ ปัญหาส่วนใหญ่ที่เราเจอส่วนมากสามารถเขียน cost function ในรูป convex function ได้) จุดมุ่งหมายของการใช้ Gradient descent ได้คือเราอยากจะหาค่า \( z \) ที่เมื่อเราทำการอัพเดทพารามิเตอร์ \( x \) แล้วทำให้สมการข้างล่างนี้เป็นจริง
\[f(z) \geq f(x) + \nabla f(x)^T (z-x) + \frac{\ell}{2}\|z-x\|^2\]และนอกจากนั้นเราสามารถเขียนว่าฟังค์ชันมีความ smoothness หรือว่า การกระโดดแต่ละขั้น gradient ยังอยู่อย่างจำกัดประมาณนี้ \( \lVert \nabla f(x) - \nabla f(z) \rVert \leq L \lVert x - z \rVert \) โดย \( L \) นี้คือ Lipscitz constant ส่วนสมการนี้เรียกว่า Lipscitz condition
ต่อมาเราสมมติว่ามี convex cost function มาตรฐาน เช่น \( f(\mathbf{x}) = \frac{1}{2} \mathbf{x}^T A \mathbf{x} - \mathbf{b}^T \mathbf{x} \) เราหา gradient ของสมการนี้ได้คือ \( \nabla f(\mathbf{x}) = A\mathbf{x} -\mathbf{b} \) ซึ่งจริงๆแล้วคำตอบของสมการนี้ ก็แก้เหมือนแคลคูลัสเลย นั่นคือ \( \nabla f(\mathbf{x}) = 0 \) หรือ \( \mathbf{x} = A^{-1}\mathbf{b} \) นั่นเอง
แล้วทำไมเราไม่คำนวณ \( A^{-1} \) โดยตรงเลยหล่ะ? นั่นก็เพราะการคำนวณ \( A^{-1} \) นั้นใช้การคำนวณมากขั้นกว่า การอัพเดทโดยใช้ gradient หรือ \( \nabla f(\mathbf{x}) \) มาก ดังนั้นการใช้ gradient descent สำหรับการประมาณพารามิเตอร์ที่ใหญ่ขึ้นมากๆจึงจำเป็นในกรณีนี้
เพราะฉะนั้น เมื่อเรามี convex function แล้ว ใน gradient descent algorithm ถ้าเราไปในทิศทางที่ถูกต้อง และมี step parameter หรือ learning rate ที่เหมาะสมแล้ว การอัพเดทในแต่ละครั้ง หรือ \( x_{k+1} = x_{k} - t_k \nabla f(x_{k}) \) ก็จะลู่เข้าสู่จุดต่ำสุดเช่นกันนี่เอง
สรุป
เรายังไม่ได้พูดถึงทฤษฎีของ Gradient descent และอีกหลายตัวอย่างเช่นการแก้ \( \ell_1 \)-regularization problem (Lasso problem) ที่มักจะเจอกันใน Machine Learning และ Compress Sensing ซึ่งในโพสต์หน้าเราจะอธิบายลงลึกกว่านี้
เราคิดว่า Gradient Descent เป็นอัลกอริทึมที่จำเป็นมากๆ แต่ไม่ได้นำมาสอนในคาบเรียนสมัยปริญญาตรี โดยส่วนตัวชอบบทความของ Moritz Hardt ซึ่งเป็น senior research scientist ที่ Google และ program committees ของ conference ดังๆมากมายเช่น ICML มากๆ เค้าพูดถึงว่าตอนเค้าเรียนในมหาฯลัยช่วงปริญญาตรีไม่ได้สอน gradient descent เลย กว่าจะได้เริ่มเรียน gradient descent ก็ในช่วงปริญญาโทกับปริญญาเอก ซึ่งจริงๆแล้วเนื้อหาหลักๆนั้นใช้เวลาเพียงสองถึงสามคาบเท่านั้น แล้วทำไมเราไม่เริ่มสอน Gradient Descent ให้กับเด็ก ป. ตรี หล่ะ? มหาฯลัยควรเริ่มสอน Gradient descent ตั้งแต่ปริญญาตรี ซึ่งสามารถนำไปเชื่อมโยงในสายวิชาแขนงอื่นๆ ซึ่งใช้พื้นฐานความคิดเดียวกัน
ในปัจจุบัน มหาวิทยาลัยหลายแห่งในต่างประเทศตอนนี้เริ่มสอน Gradient descent อย่างจริงจังแล้ว ส่วนบ้านเรา คงจะต้องมาลองดูกันว่า Gradient descent จะถูกใส่เข้าไปในการเรียนการสอนของภาควิชาวิศวกรรมไฟฟ้าหรือคอมพิวเตอร์หรือสาขาใกล้เคียงไม่?