![[Tutorial] Python for Business ฉบับพ่อค้า Part 1](https://tupleblog.github.io/images/post/python_for_business/cover.png)

ในการทำธุรกิจสิ่งที่ขาดไม่ได้เลยคือ การบันทึกบัญชีว่าการเงินเป็นยังไง อะไรขายดี สินค้าคงเหลือเป็นยังไง ซึ่งโปรแกรมบัญชีส่วนใหญ่ทำได้ดีครับ และสามารถ Export Data ต่างๆ ให้เราได้
แต่ส่วนใหญ่ก็ Export ได้ทีละรายงาน ทำให้เราต้องดูข้อมูลสลับรายงานไปมา ทำให้หลายท่านเลือกที่จะสร้างไฟล์ Excel รวมข้อมูลขึ้นมา แต่ทำทุกวันก็เหนื่อยอยู่ครับ
วันนี้เราจะเขียน Script (Python Commands) ฉบับแม่ค้ากัน ใช้ประหยัดเวลาสำหรับทำรายงาน Routine ในขณะที่สามารถสร้างรายงานสรุปการค้าไว้เช็คสุขภาพธุรกิจของทุกท่านได้ทุกวันด้วยครับ
ความคาดหวัง
Tutorial นี้อยู่ระดับกึ่งๆ Beginner จะไม่ได้โชว์พลัง Machine Learning, Sales Prediction หรือ Recommendation System แต่ว่าเราจะจัดเรียง Data ต่างๆ และแปลงเป็น Useful information ครับผม
Tutorial นี้ก็ไม่ใช่ Python 101 ด้วย ฉะนั้นผู้เขียนใช้วิธีชี้แจงโค้ดโดยการบอกผลลัพธ์ที่อยากได้สำหรับแต่ละโค้ดในตัวอย่างแทนการทำความเข้าใจทีละ Command นะครับ
ถ้าผู้อ่านรู้สึกอึดอัดใจว่าโค้ดนี้นั้นโน้นใช้ยังไง สามารถดูเพิ่มเติมได้จาก YouTube โดย Jonathan Rocher หรือ Google ครับ
เครื่องมือทำมาหากิน
Tutorial นี้ใช้ Jupyter Notebook (Anaconda) ถ้าใครยังไม่เคยมี ก็ติดตั้งให้เรียบร้อยก่อนครับ
สำหรับเนื้อหาครั้งนี้ ขอขอบคุณ 425degree.com ที่เอื้อเฟื้อข้อมูลเบื้องตันให้ ข้อมูลได้ถูกดัดแปลงเพื่อให้เหมาะกับ Tutorial ในครั้งนี้ ซึ่งผมรวมไว้ที่ลิ้งนี้แล้วครับ
ผู้อ่านท่านใดสนใจซื้อ เคส กระเป๋า หูฟัง เรียนเชิญที่ร้านนี้ครับ สั่งง่าย ส่งไว ได้ของชัวร์ครับ
เริ่มเนื้อหาจริงๆละ !!
ขอสมมติว่าโปรแกรมบัญชีของเราสามารถ Export ไฟล์ Excel สำหรับข้อมูลยอดขาย ข้อมูลกำไรรายสินค้า ข้อมูลสินค้าคงเหลือได้ และ เป้าหมายที่เราจะทำคือ สร้าง 1. รายงานสรุปยอดสินค้าขายต่อวันเทียบสินค้าคงเหลือ 2. รายงานสรุปกำไรรายสินค้าต่อวันเทียบจำนวนคงเหลือนะครับ
เรามาลำดับงานกันก่อนเลยครับ ว่าจะทำอะไรกันบ้าง
Part 1 (เนื้อหาของ Post นี้)
- อ่านข้อมูลจาก Spreadsheet ที่ต้องการ (Load Data)
- เตรียมข้อมูลให้พร้อมในการใช้งาน (Clean Data)
- แสดงผลแบบ Pivot Table และ เขียนกลับไปเป็น Spreadsheet (Export Data)
Part 2
- เขียน Function Search สินค้า (Filter Data)
- Plot Graph ให้เห็นภาพรวม (Data Visualization)
Load Data
Python เป็นภาษาโปรแกรมแบบ General Purpose ทำได้หลายอย่างครับ แต่วันนี้เราจะโฟกัสในส่วนของการอ่าน / แปลง / แสดงผล / เขียน ข้อมูลประเภท Speard Sheet ซึ่งในกรณีนี้เราจะใช้ Pandas และ NumPy ในการทำงานครับ ก่อนอื่นก็เปิด Jupyter Notebook แล้วก็ import Library มาก่อนเลยครับ
import numpy as np
import pandas as pd
ลองใช้ Pandas ในการอ่านไฟล์ Excel แล้วแสดงผลมาดูซักทีว่าได้อะไรออกมา เริ่มด้วยการตั้ง variable ตระกูล df (ย่อมาจาก Dataframe) ออกมารองรับข้อมูลยอดขายครับ
df_collections = pd.read_excel('ยอดขาย_Sample.xlsx', sheetname='Sheet2')
df_collections
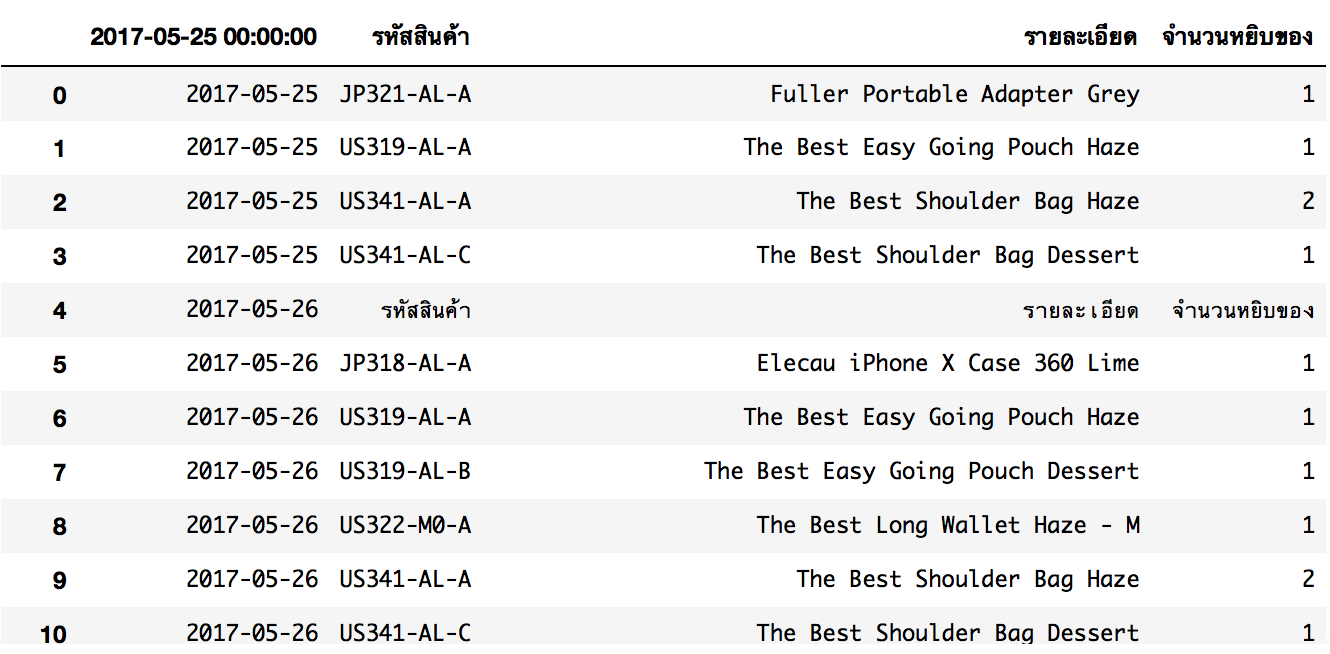
จริงๆ ผมโกงนิดนึง ตรงที่รู้ว่าข้อมูลอยู่ Sheet ชื่ออะไรครับ แต่เอาเป็นว่าถ้าไฟล์มีหลาย Sheet เราต้องเจาะจงไว้ด้วยครับ
Clean Data
ลองอ่านข้อมูลคร่าวๆ แล้วก็เห็นได้ว่าข้อมูลมีขาดๆเกินๆบ้าง เช่น มีคำว่า “รหัสสินค้า” โผล่มาทุกๆ วันที่ใหม่ เราต้องจัดให้เข้ารูปเข้ารอยหน่อย
อย่างแรกเลย เราจะลบรหัสสินค้าที่ไม่มี - ออก รหัสพวกนี้ถือว่าไม่เป็น SKU สำหรับการขายครับ [ผมพอจะรู้ภายในบริษัทว่า SKU ที่ไม่มี - ไม่ได้เป็นสินค้าสำหรับขาย เราจึงไม่ต้องนับ stock]
อย่างที่ 2 จัดรหัสสินค้าให้เป็น index คิดถึงรหัสสินค้าว่าเป็น ID ก็ได้ครับ ส่วนนี้ใช้เป็นตัวชี้อ้างอิง (Pointer) สำหรับดึงข้อมูลจาก Dataframe อื่นๆ มาใช้ได้อย่างแม่นยำครับ
มาดูไฟล์ยอดขายกันอีกที : เราอ่านไฟล์, ลบรหัสสินค้าที่ไม่มีอักษร -, set index โดยใช้ SKU, เปลี่ยนชื่อ Column วันที่, sort_index
df_collections = pd.read_excel('ยอดขาย_Sample.xlsx', sheetname='Sheet2')
df_collections = df_collections[df_collections['รหัสสินค้า'].str.contains('-') == True]
df_collections.set_index('รหัสสินค้า', inplace=True)
df_collections.rename(columns={df_collections.columns[0] : 'วันที่'}, inplace=True)
df_collections.sort_index(inplace=True)
inplace=True : จะเป็นการเปลี่ยนแปลงข้อมูลที่อยู่ในตัวแปรโดยตรง ถ้าเราไม่กำหนด เราจะต้องใช้ df_collections = df_collections.sort_index() แทนครับ
ไหนลองอ่านดูสิว่า Commands ด้านบนให้ผลเป็นยังไง
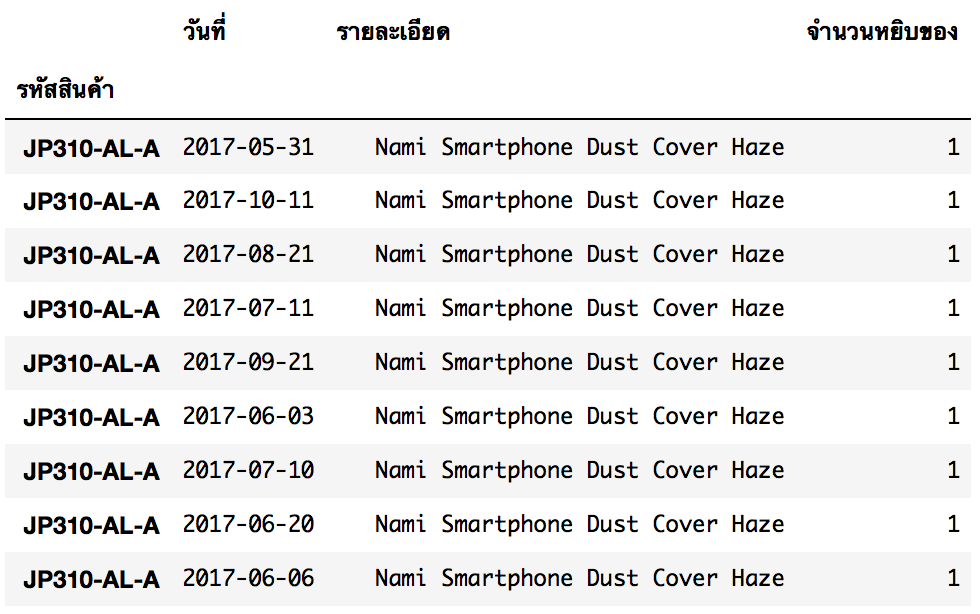
ลองมาอ่านไฟล์อื่นๆ ที่จำเป็นบ้างครับ อย่าลืมเช็คนามสกุลของไฟล์ที่อ่านด้วยนะครับ โดยที่เราจะ Clean รหัสสินค้า และ จัดรหัสสินค้าให้เป็น index
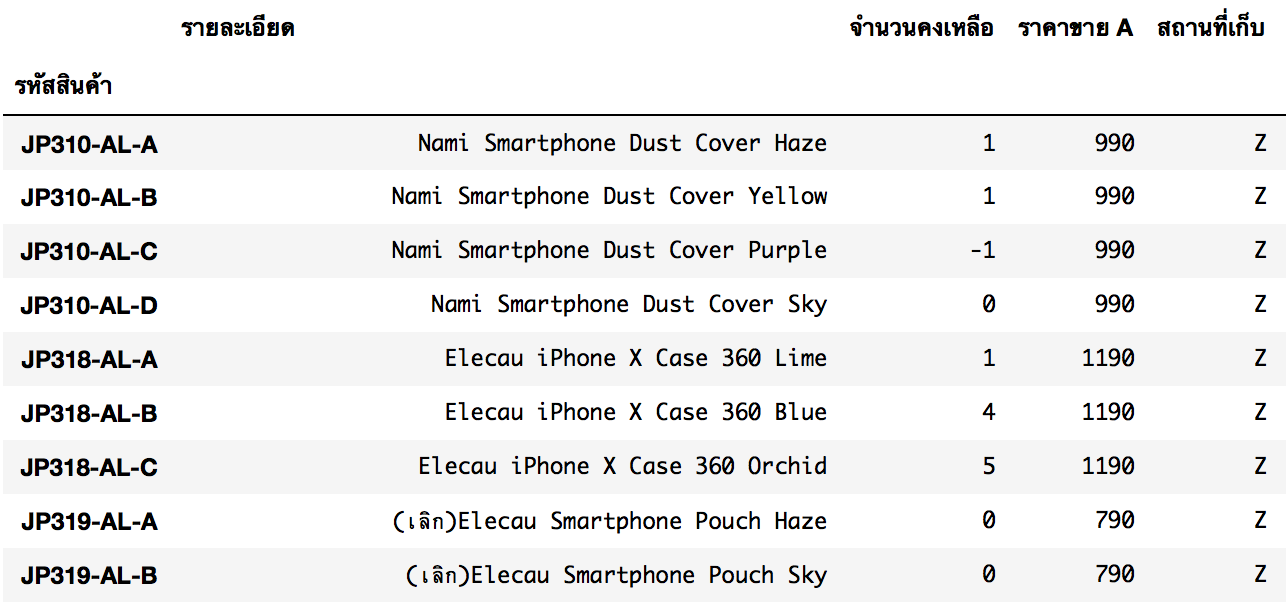
ไฟล์สินค้าคงเหลือ : อ่านไฟล์, เลือกรักษาข้อมูลเฉพาะ SKU ที่มี - เท่านั้น, set index และ เรียงลำดับ
df_Stock = pd.read_excel('stock_Sample.xls', 'Stock_Update') # sheetname ชื่อ 'Stock_Update'
df_Stock = df_Stock[df_Stock['รหัสสินค้า'].str.contains('-') == True]
df_Stock.set_index('รหัสสินค้า', inplace=True)
df_Stock.sort_index(inplace=True)
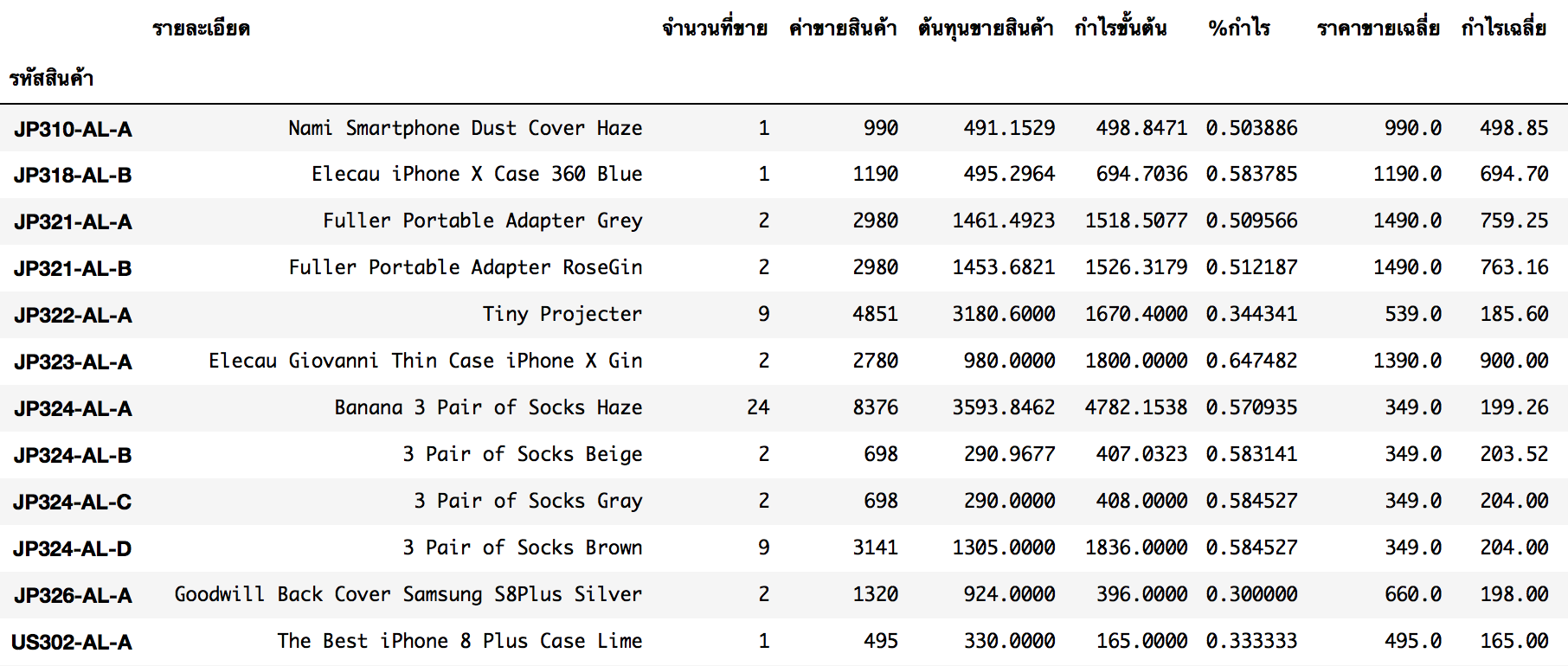
ไฟล์ต้นทุนสินค้า : อ่านไฟล์โดยเลือก Column, สินค้าที่ราคาเป็น 0 และไม่มี - ถูกตัดออก, set index, เพิ่มเติมข้อมูลที่จำเป็น เช่น ‘%กำไร’, ‘ราคาขายเฉลี่ย’ และ ‘กำไรเฉลี่ย’
# COGS and GP
file_Inventory_name = 'Inventory_Sample.xls'
# sheetname ชื่อ 'Inventory_Sample’ และเลือกอ่านบาง Column
df_Inventory = pd.read_excel(file_Inventory_name, sheetname=file_Inventory_name[:-4], parse_cols=[0,1,4,5,6,7])
df_Inventory = df_Inventory[df_Inventory['ค่าขายสินค้า'] > 0][df_Inventory['รหัสสินค้า'].str.contains('-') == True]
df_Inventory.set_index('รหัสสินค้า', inplace=True)
df_Inventory['%กำไร'] = df_Inventory['กำไรขั้นต้น'] / df_Inventory['ค่าขายสินค้า']
df_Inventory['ราคาขายเฉลี่ย'] = df_Inventory['ค่าขายสินค้า'] / df_Inventory['จำนวนที่ขาย']
df_Inventory['กำไรเฉลี่ย'] = (df_Inventory['ราคาขายเฉลี่ย'] * df_Inventory['%กำไร']).round(decimals=2)
df_Inventory.sort_index(inplace=True)
สำหรับข้อมูลยอดขาย มีบางช่องที่เป็นช่อง Missing Data ครับ
df_collections.describe()
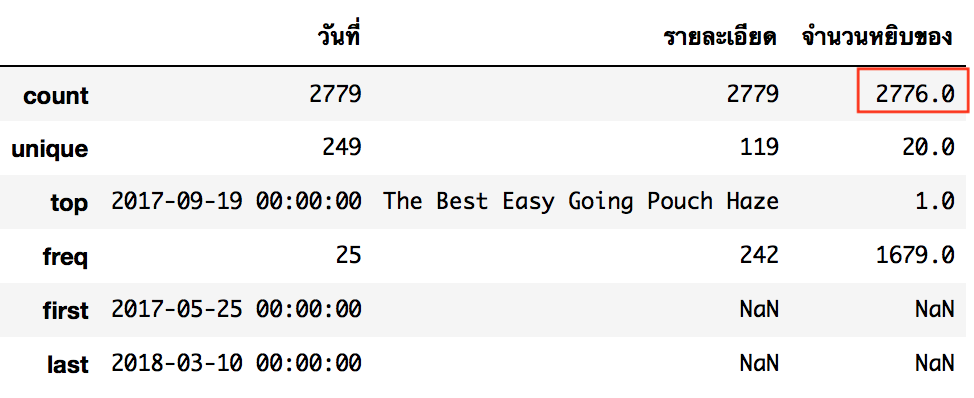
การจัดการ Missing Data มีหลากหลายรูปแบบเช่น เติมจากช่องก่อนหน้า, เติมโดยใช้ค่าเฉลี่ย, ฯลฯ แต่ผมพอรู้ว่าแบบนี้เป็นการยืมของภายในร้านค้าเท่านั้น ก็เลือกที่จะตัดทิ้งไปเลยครับ
Command นี้ ผมเปลี่ยนข้อมูลในช่อง ‘จำนวนหยิบของ’ ให้เป็นตัวเลข และถ้าไม่ใช่เลขก็ให้กลายเป็นช่องโบ๋ รวมทั้ง เช็คว่าช่องดังกล่าวมีข้อมูลอยู่ด้านในหรือไม่ โดยเราจะคัดเฉพาะช่องที่มีข้อมูล (ช่องไม่โบ๋) ไปใช้งานต่อ เทคนิคนี้เรียกว่า Masking ครับ (เลือกเฉพาะข้อมูลที่มีค่า True)
df_collections = df_collections[pd.isnull(pd.to_numeric(df_collections['จำนวนหยิบของ'], errors='coerce')) == False]
df_collections.describe()
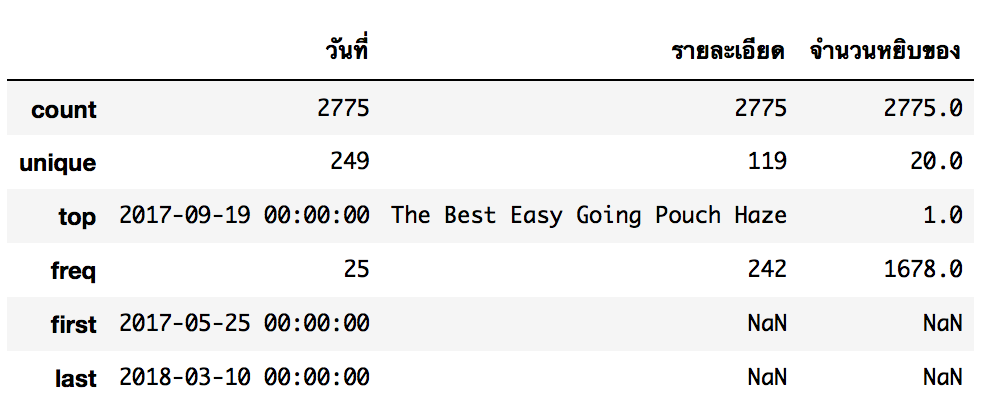
ผมรู้สึกว่า SKU ตอนนี้มีความละเอียดสูงมาก แยกสีแยกรุ่นให้เราครบเลย อาจจะไม่เป็นประโยชน์ในการมองภาพรวมมากนัก เราจะเตรียมข้อมูลสำหรับทำ Grouping ไว้ด้วย โดยสร้าง Column สำหรับ SKU ที่หยาบขึ้นครับ
.index.map(lambda x : x.rpartition('-')[0]) คำสั่งนี้ไว้ตัดคำครับ คำที่นี่คือ index หรือ SKU นั่นเอง โดยตำแหน่งตัดคำคืออักษร - ตัวแรกนับจากด้านหลัง และสร้าง Column ใหม่สำหรับรองรับข้อมูลชื่อ SKU_8digits
df_collections['SKU_8digits'] = df_collections.index.map(lambda x : x.rpartition('-')[0])
df_Inventory['SKU_8digits'] = df_Inventory.index.map(lambda x : x.rpartition('-')[0])
df_Stock['SKU_8digits'] = df_Stock.index.map(lambda x : x.rpartition('-')[0])
df_Stock
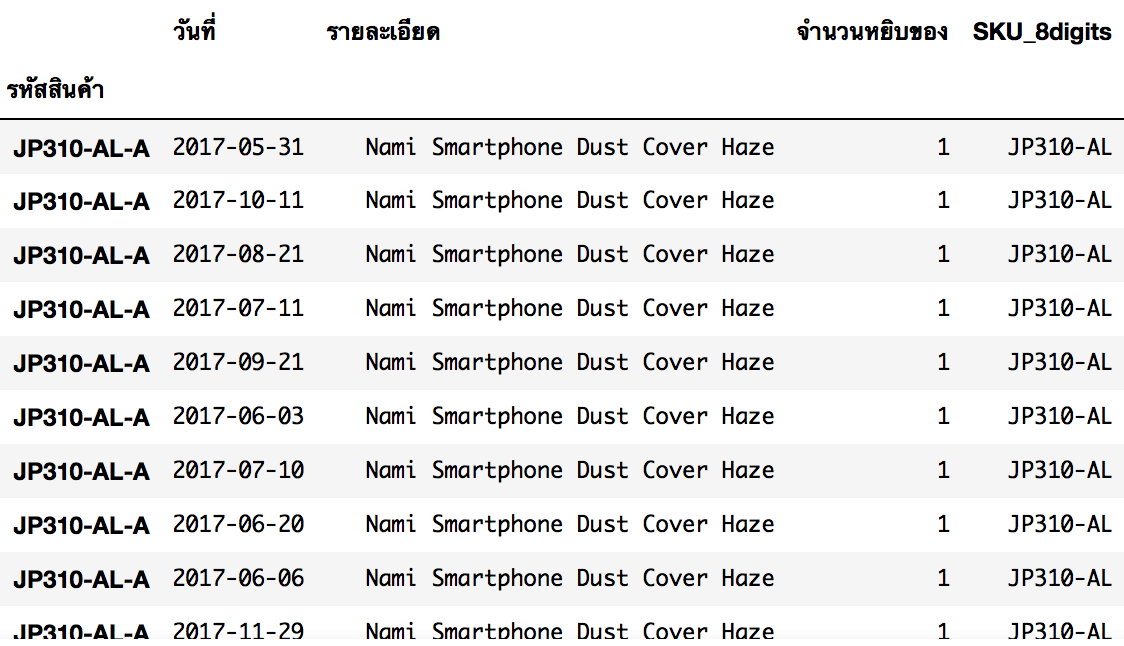
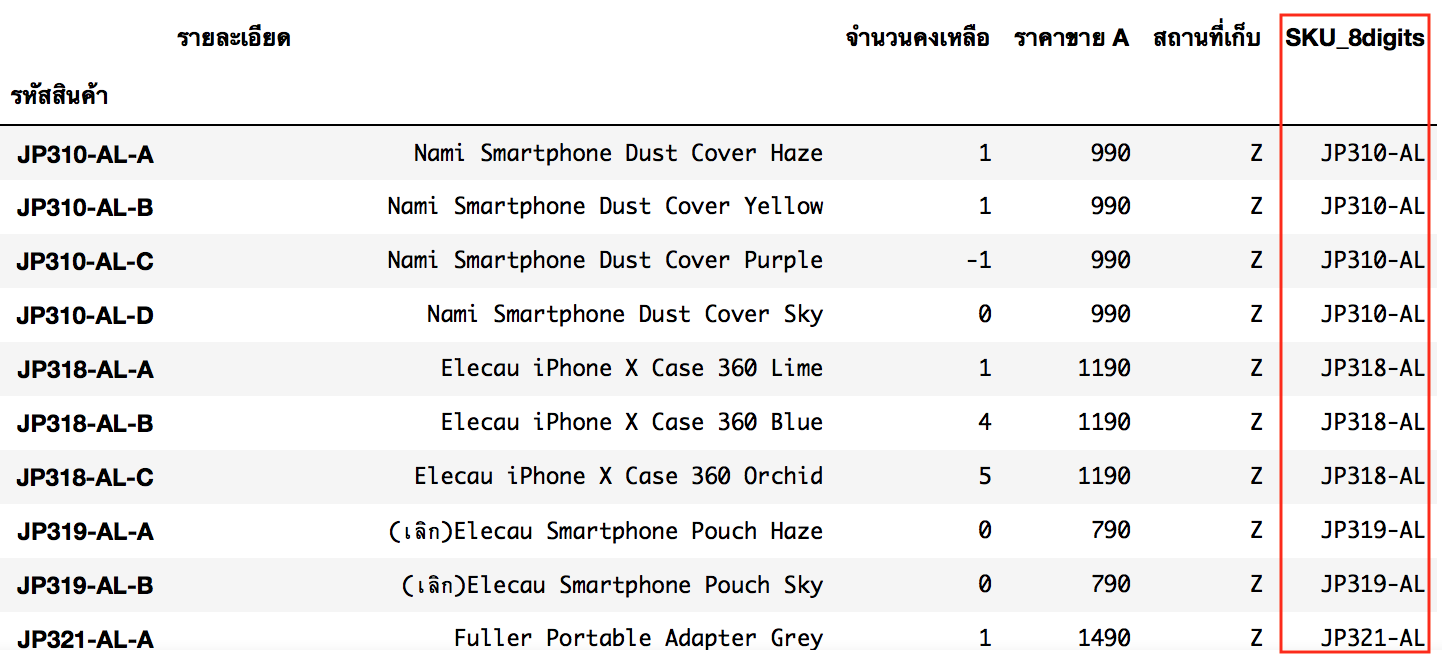
นอกจากนี้แล้วก็ทดลองดึงข้อมูลข้ามมาจาก Dataframe อื่นๆ วยซะเลย
.join() ทำหน้าที่เหมือน vlookup ใน MS Excel ครับ โดยใช้ index ที่เราเซ็ตไว้เป็น reference ในการดึงข้อมูลระหว่าง 2 Dataframe ครับ
df_collections = df_collections.join(df_Inventory['กำไรเฉลี่ย'])
df_collections = df_collections.join(df_Stock['ราคาขาย A'])
‘กำไรเฉลี่ย’ เราสร้างมาจากการหาร อาจให้ผลหารเป็น inf, -inf ได้ครับ ถ้าตัวหารเป็น 0 ซื่งผมเลือกที่จะแปลงค่าเป็น NaN (ช่องโบ๋) แทนครับ
df_collections = df_collections.replace([np.inf, -np.inf], np.nan)
ซึ่งช่องโบ๋ทำให้ข้อมูลกำไรเฉลี่ยเป็น Missing Data ผมแก้เกมโดย Assume กำไรจากราคาขายปลีก 30% และ กำไรรวม = กำไรเฉลี่ย x จำนวนขายได้
df_collections.loc[:,('กำไรเฉลี่ย')][np.isnan(df_collections['กำไรเฉลี่ย'])] = df_collections['ราคาขาย A'] * 0.3
df_collections['กำไรXจำนวน'] = (df_collections['จำนวนหยิบของ'] * df_collections['กำไรเฉลี่ย'])
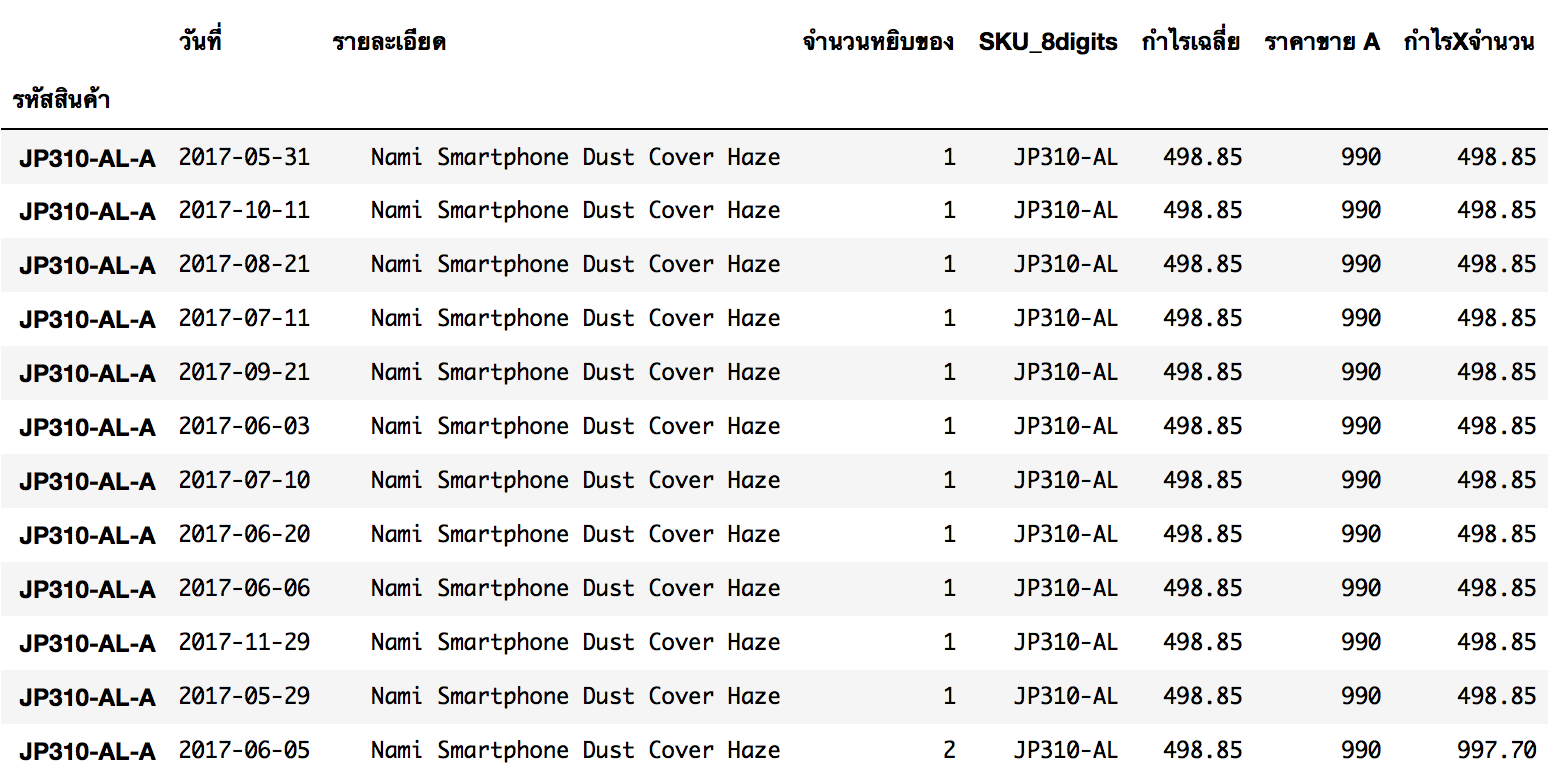
Pivot Table
อธิบาย Pivot Table สั้นๆ แปลได้ว่า การ flatten data ลงมาครับ เรียกได้ว่าเป็นการสรุปแบบนึงนั่นแหละ
เริ่มกันด้วยการ Pivot จำนวนขายแต่ละวัน โดยรวมจำนวนกล่อง และจำแนกตามวันที่และ SKU ครับ
# จำนวนกล่อง
pivot_Order_box = df_collections.pivot_table(values='จำนวนหยิบของ',
index=['รหัสสินค้า'],
columns=df_collections.columns[0],
aggfunc=sum)
pivot_Order_box
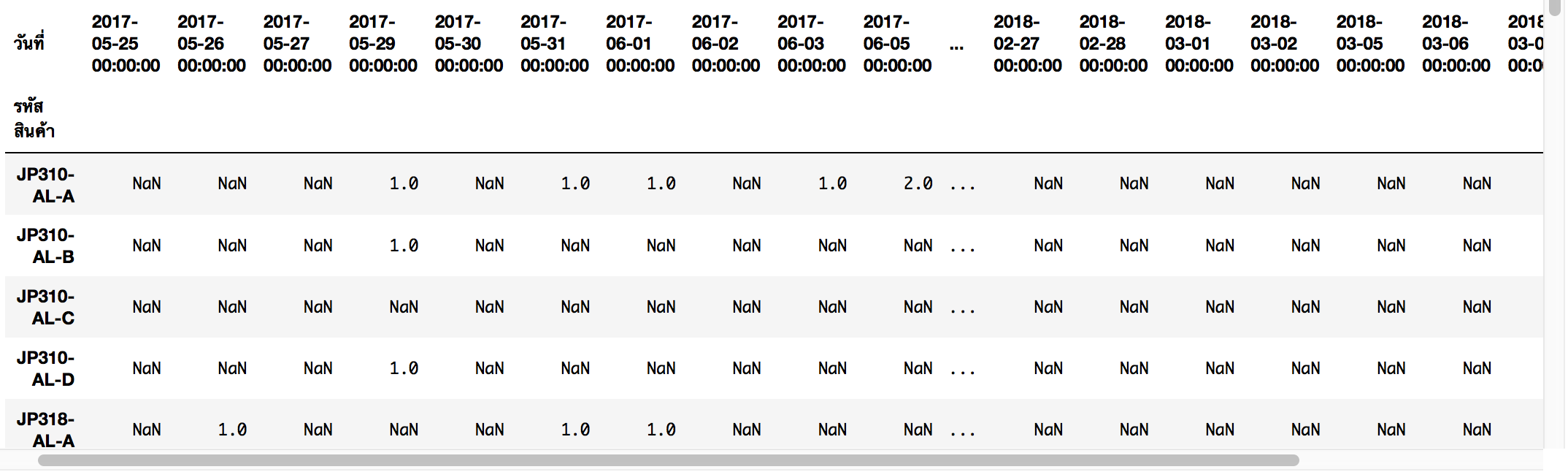
Column เดิมใช้ Timestamp เลยต้องจัดวันที่ใหม่ให้อ่านง่ายขึ้นครับ
pivot_Order_box.columns = pivot_Order_box.columns.map(lambda x : x.strftime("%d-%m-%y"))
นอกจากนี้เราจะรวมยอดขายตลอดกาลของแต่ละ SKU, ยอดขาย 7 วัน ย้อนหลัง, เทียบสินค้าคงเหลือ
pivot_Order_box['Grand Total'] = pivot_Order_box.sum(axis=1)
pivot_Order_box = pivot_Order_box.join(df_collections['รายละเอียด']).join(df_Stock['จำนวนคงเหลือ'])
pivot_Order_box['Sum7D'] = pivot_Order_box[pivot_Order_box.columns[-10:-3]].sum(axis=1)
pivot_Order_box = pivot_Order_box[~pivot_Order_box.index.duplicated()]
เลขติดลบ คือตำแหน่ง Column นับจากหลังสุดครับ -1 คือแถวหลังสุด -2 แถวรองหลังสุด
บรรทัดล่างสุดเอาไว้แก้ duplicated Row ซึ่งปัญหานี้อาจเกิดได้หากข้อมูลที่เราเอามา .join() มี Key ซ้ำ (อ่านเพิ่มเติมได้จากลิ้งนี้ครับ)
เรียบร้อยแล้วครับกับเป้าหมายแรกของเรา : รายงานสรุปยอดสินค้าขายต่อวันเทียบสินค้าคงเหลือ

มาลองทำ Pivot อีกครั้งครับ ทีนี้ใช้ข้อมูลทางฝั่งกำไรกันบ้าง จะได้เห็นเม็ดเงินที่ธุรกิจทำได้
โดยครั้งนี้เราเปลี่ยน index ให้เป็น ‘SKU_8digits’ เพื่อจะได้ ignore ความต่างเล็กๆน้อยๆของ SKU ต่างๆ เช่น สี, ขนาด เป็นต้น
pivot_Order_profit = df_collections.pivot_table(values='กำไรXจำนวน',
index=['SKU_8digits'],
columns=['วันที่'],
aggfunc=np.sum)
แล้วเราก็แปลงวันที่, ทำ Columns รวมเลขย้อนหลังทั้งแบบตลอด และ แบบ 7 วัน เหมือนเดิม
ที่เพิ่มเติมคือเรา .join() ข้อมูล ‘รายละเอียด’ และ จำนวนคงเหลือแบบรวมทุกสี / ขนาดเข้ามาด้วย (ต้อง pivot_table แบบ sum เข้ามา)
pivot_Order_profit.columns = pivot_Order_profit.columns.map(lambda x : x.strftime("%d-%m-%y"))
pivot_Order_profit['Grand Total'] = pivot_Order_profit.sum(axis=1)
pivot_Order_profit = pivot_Order_profit.join(df_collections.reset_index().set_index('SKU_8digits')['รายละเอียด'])
pivot_Order_profit['GrossProfit7D'] = pivot_Order_profit[pivot_Order_profit.columns[-9:-2]].sum(axis=1)
pivot_Order_profit = pivot_Order_profit.join(df_Stock.pivot_table(values='จำนวนคงเหลือ',index=['SKU_8digits'],aggfunc=np.sum))
แน่นอนครับ ว่านี้ต้องเป็น รายงานสรุปกำไรรายสินค้าต่อวันเทียบจำนวนคงเหลือ ที่เรารอคอย!
pivot_Order_profit
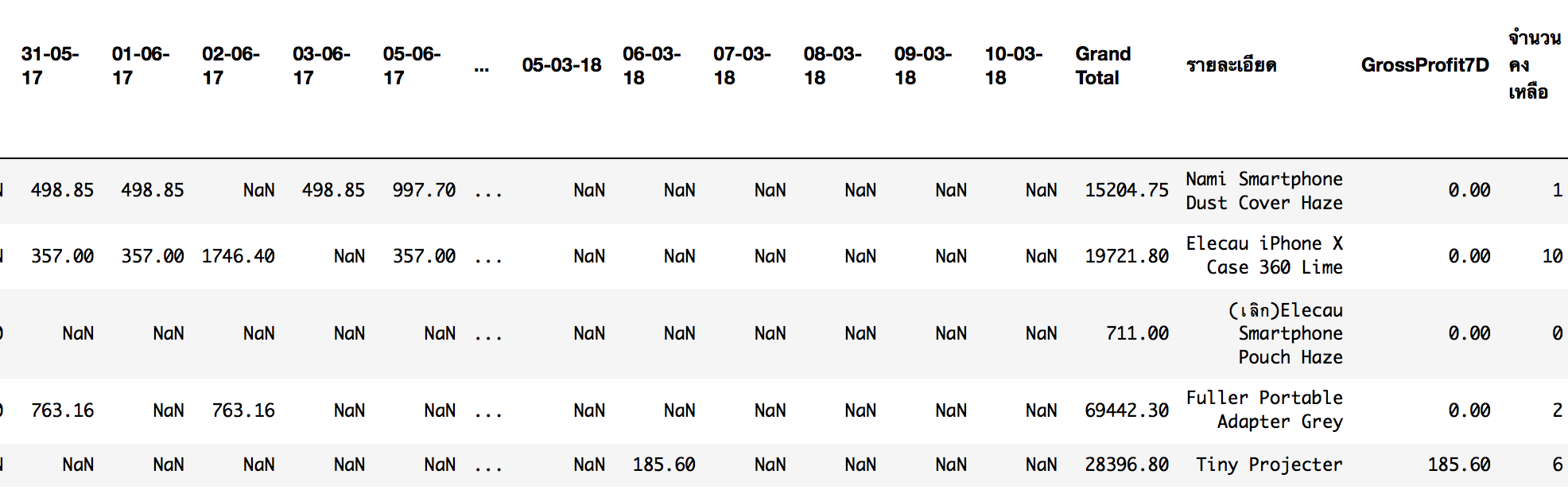
โอเค! ทุกอย่างลงตัว Export เป็น MS Excel ไว้ดูเล่นได้ โดยเราจะทำ 2 file สำหรับแจกแจงข้อมูลยอดขาย และ ข้อมูลกำไร
%cd ~/Desktop/
with pd.ExcelWriter('box_ย้ายแล้วจ้า.xlsx') as writer:
pivot_Order_box.to_excel(writer, sheet_name='All')
%cd ~/Desktop/
with pd.ExcelWriter('profit_ย้ายแล้วจ้า.xlsx') as writer:
pivot_Order_profit.to_excel(writer, sheet_name='All')
%cd เป็น unix command เอาไว้เลือก Export location ครับ โดยผมใช้ Desktop แบบชิวๆ
with เป็น Good Practice ในการทำ Export ครับ คือปกติในการทำ Export เราจะต้องเปิดไฟล์ก่อน ซึ่งคำสั่ง with จะทำให้แน่ใจว่า หลังจบ session python จะปิดไฟล์ให้ด้วยครับ
อย่าลืมไปเช็คว่าที่ Directory มีไฟล์โผล่ขึ้นมาไหมด้วยนะครับ

เพียงเท่านี้เราก็ได้รายงานสุขภาพธุรกิจของท่านประจำวันแล้วครับ ต่อไปก็ไม่ต้องไล่ดูที่ละรายงาน ข้ามไปข้ามมา หรือมาคอยกดรายงานด้วยมือทุกๆวันแล้วครับ :))
สรุป Part 1
ในส่วนนี้เราได้ใช้ Python ในการเตรียมรายงานภาพรวมธุรกิจให้เราแทนที่เราจะต้องมานั่งกดสูตรทุกๆครั้งที่ทำรายงานนี้ และ Export รายงานนี้ออกมา ทีเด็ดคือ เมื่อชุดคำสั่งข้างบนลงตัวพร้อมใช้งานแล้ว เราสามารถรันรวดเดียวได้เลยและรันได้ทุกเวลาด้วย เหมาะกับรายงานที่ต้องทำเป็นประจำ
สำหรับ Part 2 จะเป็นการสาธิตวิธีใช้ Python ฉบับพ่อค้าในการค้นหารายละเอียดสินค้า และทำ Data Visualization อย่างง่ายกันครับ
โปรดติดตามตอนต่อไป และ ขอกราบสวัสดี
ขอบคุณจารย์ตุลย์ @bluenex และ จารย์มาย @titipata ที่ช่วยพิสูจน์อักษร